Les principaux objets en jeu dans le théorème sont :
- Les m entrées de ton réseau de neurones
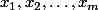
, qui sont des réels entre 0 et 1 (en jargon on parle d'un vecteur x en dimension m).
- Une fonction f, qui prend les m entrées et renvoie un réel
)
. C'est la fonction qu'on cherche à "imiter" avec un réseau de neurones.
- La fonction F, qui prend les m entrées et renvoie un réel
)
. C'est la fonction qui décrit le réseau de neurones, le but du jeu est que F ressemble le plus possible à f, autrement dit que la sortie du réseau de neurones
soit la plus proche possible de
pour toutes les valeurs possibles des entrées
.
En arrière-plan, il y a d'autres objets qui servent à caractériser le réseau de neurones, c'est-à-dire à définir la forme que peut avoir la fonction F. Pour comprendre ce passage il faut connaître en détail le fonctionnement d'un simple réseau de neurones (du type perceptron simple couche, si le nom te dit quelque chose) :
Chaque neurone individuel, lorsqu'il reçoit les entrées
, commence par appliquer une fonction affine pour obtenir un réel, c'est-à-dire qu'il calcule un nombre
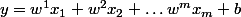
(je note volontairement les indices des w en exposant pour éviter d'entrer en conflit avec les notations de l'énoncé, mais ce sont bien des indices, pas des puissances). On préfère écrire y en notation matricielle,
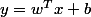
où w est le "vecteur poids"
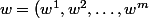)
et x est le "vecteur entrée"
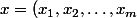)
. Il donne ensuite ça à sa fonction d'activation
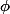
(qui prend un réel et renvoie un réel) pour obtenir à sa sortie le nombre
 = \phi(w^Tx + b))
.
Dans ton réseau de neurones, tous les neurones ont la même fonction d'activation,
, mais ils ont le droit d'utiliser des coefficients différents, c'est-à-dire que le neurone numéro i a son propre vecteur poids
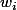
et son propre coefficient
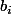
, et sa sortie est donc donnée par
)
.
Finalement, la sortie du réseau de neurones, qu'on note
 = F(x_1,x_2,\dots , x_m))
, est calculée par une fonction linéaire des sorties de chaque neurone. La sortie du neurone numéro i est affectée d'un coefficient
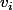
, et on fait la somme pour tous les neurones. S'il y a N neurones dans ton réseau, ça donne
 = v_1\phi(w_1^Tx + b_1) + v_2\phi(w_2^Tx + b_2) + \dots + v_N\phi(w_N^Tx + b_N))
, qui peut s'écrire plus simplement
 = \sum_{i=1}^N v_i\phi(w_i^Tx + b_i))
.
Bref, une fois tout ça décortiqué, ce que le dit le théorème c'est que si tu te fixes une fonction d'activation
"pas trop moche", alors tu pourras toujours programmer des approximations aussi précises que tu veux de n'importe quelle fonction continue en utilisant un réseau de neurones avec la fonction
. Ce que le théorème ne te dit
pas c'est comment le programmer en pratique, c'est-à-dire comment bien choisir tes coefficients, de combien de neurones tu as besoin, etc.


