On cherche à concevoir un système de type logiciel qui permet de détecter les spams.
Soit Pm, la probabilité qu'un spam contienne le mot M
Qm, la probabilité qu'un courrier légitime contienne le mot M
Soit M l'évènement : {le mail contient le mot M}
Et S l'évènement : {le mail est un spam}
Le système connait également la proportion H de spams parmi tous les courriers qu'il a déjà analysés.
=> I. Exprimer Pm et Qm à partir de M et S. Que représentent 1-Pm et 1-Qm? De quelle probabilité H est-il une approximation?
Mes réponses :*Pm = P ( M sachant S) ; Qm = P ( M sachant S_)
*1-Pm est la probabilité qu'un spam ne contienne pas le mot M
1-Qm est la probabilité qu'un courrier "sain" ne contienne pas le mot M
*H est la probabilité qu'un mail soit un spam après x analyses
Jusque là çà va (enfin je croît^^)
Ensuite on dit qu'un algorithme a analysé le contenu du message et a renvoyé une liste L de mots.
L est l'évènement : { le mail contient les mots de la liste L}
On suppose que les apparitions de chaque mot de la liste L sont des évènements indépendants et conditionnellement indépendants selon S et S_.
=> Calculer la probabilité que le mail soit un spam en fonction de Pm, Qm et H.
Voilà, çà fait plusieurs heures que je suis dessus et toujours rien
Aidez-moi SVP :happy2:
Probabilités niveau bac+2, pas évident
15 messages
- Page 1 sur 1
![]() par yos » 20 Avr 2007, 15:49
par yos » 20 Avr 2007, 15:49
Bonjour.
Tu peux enlever "après x analyses" et rajouter "approximativement".
Quel message? La fin est confuse. Tu as peut-être un peu trop tranché dans l'énoncé original?
MaximeValenciennes a écrit:*H est la probabilité qu'un mail soit un spam après x analyses
Tu peux enlever "après x analyses" et rajouter "approximativement".
MaximeValenciennes a écrit:Ensuite on dit qu'un algorithme a analysé le contenu du message et a renvoyé une liste L de mots.
Quel message? La fin est confuse. Tu as peut-être un peu trop tranché dans l'énoncé original?
![]() par MaximeValenciennes » 20 Avr 2007, 16:03
par MaximeValenciennes » 20 Avr 2007, 16:03
Ah oui désolé j'aurai dû employé le mot "mail".
En fait c'est un logiciel qui permet de détecter si le mail est un spam. Pour cela, auparavant, un algorithme permet de renvoyer une liste L, composée des mots du mail. (M1,M2,...,Mi)
Voila jspr que c'est plus claire
Merci encore
En fait c'est un logiciel qui permet de détecter si le mail est un spam. Pour cela, auparavant, un algorithme permet de renvoyer une liste L, composée des mots du mail. (M1,M2,...,Mi)
Voila jspr que c'est plus claire
Merci encore
![]() par fahr451 » 20 Avr 2007, 17:21
par fahr451 » 20 Avr 2007, 17:21
bonsoir
ah je trouvais aussi que c'était pas clair clair mais je me disais que c'était moi
en fait c'est toujours pas limpide i = le nombre de mots est fixé? aléatoire? si oui suivant quelle loi?
ah je trouvais aussi que c'était pas clair clair mais je me disais que c'était moi
en fait c'est toujours pas limpide i = le nombre de mots est fixé? aléatoire? si oui suivant quelle loi?
![]() par MaximeValenciennes » 20 Avr 2007, 17:30
par MaximeValenciennes » 20 Avr 2007, 17:30
fahr451 a écrit:bonsoir
ah je trouvais aussi que c'était pas clair clair mais je me disais que c'était moi
en fait c'est toujours pas limpide i = le nombre de mots est fixé? aléatoire? si oui suivant quelle loi?
Bonsoir
Non il n'est rien précisé, donc le nombre de mots n'est pas fixé. et tout ce qu'on sait sur les évènements Mi c'est qu'ils sont indépendants et conditionnellement indépendant selon S et S_
Si c'est toujours pas clair je réécris l'énoncé en entier
Merci encore :happy2:
Une question : est-ce que vous pensez qu'on puisse utiliser le théorème de Bayes ici?
![]() par fahr451 » 20 Avr 2007, 17:34
par fahr451 » 20 Avr 2007, 17:34
c'est une excellente idée d'écrire l'énoncé en entier c'est même la première chose à faire
![]() par MaximeValenciennes » 20 Avr 2007, 18:00
par MaximeValenciennes » 20 Avr 2007, 18:00
L'idée est de concevoir un système "intelligent" (au sens où son efficacité s'améliore quand on lui signale ses erreurs) basé sur la détection de certains mots dans le courrier électronique. Il se décompose donc en 2 parties :
1. Une partie "analyse", chargée de calculer la probabilité pour qu'un courrier donné soit indésirable à partir des mots qu'il contient
2. Une partie "apprentissage", révisant les paramètres de l'algorithme à partir d'une information donnée par l'utilisateur.
Pour cela, le logiciel dispose de deux catégories (spam, notée S, et ham, notée S_) et d'une liste de mots significatifs (on exclut les articles, la ponctuation, etc.).Pour chacun de ces mots M, le système "connaît" les probabilités Pm qu'un spam contienne le mot M et Qm qu'un courrier légitime contienne le mot M. Dans toute la suite, on identifie le mot M et l'évènement {le mail contient le mot M}. De même on noera S l'évènement {le mail est un spam]
Le système connaît également la proportion H de spams parmi tous les courriers qu'il a déjà analysés.
I. (je réécrit pas)
Le système est chargé d'analyser un message électronique. Un algorithme précédent a analysé le contenu du message et renvoyé une liste L de mots significatifs. On note également L l'évènement {le mail contient les mots de la liste L}
II.1 Qu'est-ce que L vis-à-vis des évènements M correspondant aux mots de la liste L?
2 On suppose que les apparitions de chaque mot de la liste L constituent des événements indépendants et conditionnellement indépendants selon S et S_. Calculez la probabilité que le mail soit un spam en fonction des probabilités Pm, Qm et H...
Voilà l'énoncé entier (au moins pour la première partie de l'exercice)
J'espère que vous pourrez m'aider
Merci :happy2:
1. Une partie "analyse", chargée de calculer la probabilité pour qu'un courrier donné soit indésirable à partir des mots qu'il contient
2. Une partie "apprentissage", révisant les paramètres de l'algorithme à partir d'une information donnée par l'utilisateur.
Pour cela, le logiciel dispose de deux catégories (spam, notée S, et ham, notée S_) et d'une liste de mots significatifs (on exclut les articles, la ponctuation, etc.).Pour chacun de ces mots M, le système "connaît" les probabilités Pm qu'un spam contienne le mot M et Qm qu'un courrier légitime contienne le mot M. Dans toute la suite, on identifie le mot M et l'évènement {le mail contient le mot M}. De même on noera S l'évènement {le mail est un spam]
Le système connaît également la proportion H de spams parmi tous les courriers qu'il a déjà analysés.
I. (je réécrit pas)
Le système est chargé d'analyser un message électronique. Un algorithme précédent a analysé le contenu du message et renvoyé une liste L de mots significatifs. On note également L l'évènement {le mail contient les mots de la liste L}
II.1 Qu'est-ce que L vis-à-vis des évènements M correspondant aux mots de la liste L?
2 On suppose que les apparitions de chaque mot de la liste L constituent des événements indépendants et conditionnellement indépendants selon S et S_. Calculez la probabilité que le mail soit un spam en fonction des probabilités Pm, Qm et H...
Voilà l'énoncé entier (au moins pour la première partie de l'exercice)
J'espère que vous pourrez m'aider
Merci :happy2:
![]() par yos » 20 Avr 2007, 21:51
par yos » 20 Avr 2007, 21:51
Je vois un truc comme ça :
un arbre avec deux branches partant de la racine : S et à chaque bout.
à chaque bout.
De chacune de ces deux branches partent deux branches avec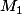 et
et  à chaque bout.
à chaque bout.
etc avec .
.
Sur les branches elle-même on met les probabilités (en fait dés le second niveau ce sont des proba conditionnelles, mais c'est celles qu'on connait ( ) vue l'hypothèse d'indépendance).
) vue l'hypothèse d'indépendance).
L est l'intersection des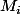 il me semble. Cela doit vouloir dire que le message est qualifié de SPAM lorsqu'il contient tous les mots de la liste L. Mais j'en suis pas certain.
il me semble. Cela doit vouloir dire que le message est qualifié de SPAM lorsqu'il contient tous les mots de la liste L. Mais j'en suis pas certain.
Ps : quelqu'un sait faire un arbre en LaTeX ?
un arbre avec deux branches partant de la racine : S et
De chacune de ces deux branches partent deux branches avec
etc avec
Sur les branches elle-même on met les probabilités (en fait dés le second niveau ce sont des proba conditionnelles, mais c'est celles qu'on connait (
L est l'intersection des
Ps : quelqu'un sait faire un arbre en LaTeX ?
![]() par fahr451 » 20 Avr 2007, 21:52
par fahr451 » 20 Avr 2007, 21:52
yos a écrit:
Ps : quelqu'un sait faire un arbre en LaTeX ?
trop facile !
![]() par MaximeValenciennes » 21 Avr 2007, 06:12
par MaximeValenciennes » 21 Avr 2007, 06:12
Merci beaucoup!
Mais j'ai une autre question : comment faire intervenir le H dans l'expression de P(S) ? :triste:
Merci :happy2:
Je viens de trouver peut-être une autre piste :
Je me place dans le cas où le mail n'a qu'un mot :
On a : P(S) = P(M sachant S) / Pm Or : P(M sachant S) + P(M sachant S_) = P(M)
D'où : P(M sachant S) = P(M) - Qm*P(S_)
On injecte dans la 1ere expression :
P(S) = (P(M) - (1-P(S))*Qm)/Pm <=> P(S) *[1-Qm/Pm] = (P(M)-Qm)/Pm
Ainsi on a : P(S) = (P(M)-Qm)/(Pm-Qm)
Ensuite avec L={M1,M2,...MN} Il faut tenir compte de leur probabilité d'apparition dans les spams. (avec le même principe). Comme L est l'intersection des Mi, et que ces derniers sont indpt et conditionnellement indpt :
P(S) = PRODUIT pour i variant de 1 à N de [(P(Mi)-Qmi)/(Pmi-Qmi)]
Le problème c'est qu'on ne connait pas P(M).
Mais peut-être qu'il intervient dans l'expression de H...(enfin c'est ce à quoi je pensais)
Voilà si vous avez le temps dites-moi ce que vous en pensez :happy2:
Merci
Mais j'ai une autre question : comment faire intervenir le H dans l'expression de P(S) ? :triste:
Merci :happy2:
Je viens de trouver peut-être une autre piste :
Je me place dans le cas où le mail n'a qu'un mot :
On a : P(S) = P(M sachant S) / Pm Or : P(M sachant S) + P(M sachant S_) = P(M)
D'où : P(M sachant S) = P(M) - Qm*P(S_)
On injecte dans la 1ere expression :
P(S) = (P(M) - (1-P(S))*Qm)/Pm <=> P(S) *[1-Qm/Pm] = (P(M)-Qm)/Pm
Ainsi on a : P(S) = (P(M)-Qm)/(Pm-Qm)
Ensuite avec L={M1,M2,...MN} Il faut tenir compte de leur probabilité d'apparition dans les spams. (avec le même principe). Comme L est l'intersection des Mi, et que ces derniers sont indpt et conditionnellement indpt :
P(S) = PRODUIT pour i variant de 1 à N de [(P(Mi)-Qmi)/(Pmi-Qmi)]
Le problème c'est qu'on ne connait pas P(M).
Mais peut-être qu'il intervient dans l'expression de H...(enfin c'est ce à quoi je pensais)
Voilà si vous avez le temps dites-moi ce que vous en pensez :happy2:
Merci
![]() par yos » 21 Avr 2007, 08:29
par yos » 21 Avr 2007, 08:29
H=P(S), donc H et 1-H sur les deux premières branches de l'arbre.
Autre chose : les règles de calcul dans les arbres contiennent entre autre la formule des probabilités totales (Bayes).Pour le reste je n'ai pas regardé. Peut-être plus tard.
Autre chose : les règles de calcul dans les arbres contiennent entre autre la formule des probabilités totales (Bayes).Pour le reste je n'ai pas regardé. Peut-être plus tard.
![]() par MaximeValenciennes » 21 Avr 2007, 09:36
par MaximeValenciennes » 21 Avr 2007, 09:36
yos a écrit:H=P(S), donc H et 1-H sur les deux premières branches de l'arbre.
Autre chose : les règles de calcul dans les arbres contiennent entre autre la formule des probabilités totales (Bayes).Pour le reste je n'ai pas regardé. Peut-être plus tard.
Merci de m'accorder du temps :jap:
Mais on veut exprimer P(S) en fonction de H, Pm, et Qm
Et H n'est qu'une approximation de P(S), donc on ne peut pas écrire H=P(S), enfin je croît
Encore merci^^
![]() par yos » 21 Avr 2007, 10:14
par yos » 21 Avr 2007, 10:14
Je ne crois pas : on cherche P(S/M) à mon avis (ou P(S/L) si plusieurs mots sont nécessaires pour que le logiciel dise "Spam" en output). Mais il est possible que je me trompe. Pour moi l'énoncé reste ambigu et flou. Si un probabiliste pouvait trancher ce serait bien.
![]() par MaximeValenciennes » 21 Avr 2007, 10:24
par MaximeValenciennes » 21 Avr 2007, 10:24
yos a écrit:Je ne crois pas : on cherche P(S/M) à mon avis (ou P(S/L) si plusieurs mots sont nécessaires pour que le logiciel dise "Spam" en output). Mais il est possible que je me trompe. Pour moi l'énoncé reste ambigu et flou. Si un probabiliste pouvait trancher ce serait bien.
A mon avis vous avez raison, çà doit être P(S|L) qu'on cherche :hein: . Cà paraît plus logique parce qu'on se place dans le cas où la liste L a été renvoyée. Donc il faut pas tenir compte des cas où cette liste n'est plus vérifiée (donc quand le mail est différent^^)
"Sachant que les mots du mail sont ....... , quelle est la probabilité pour que ce soit un spam?"
![]() par MaximeValenciennes » 21 Avr 2007, 14:18
par MaximeValenciennes » 21 Avr 2007, 14:18
Désolé de faire un double-post mais le sujet est différent :
Est-ce que la propriété "conditionnellement indépendante" est vérifiée si :
P( A intersection Bk) = P( A intersection B1) * P( A intersection B2) * ... * P( A intersection Bn) ???
Ou bien faut-il inverser les rôles de A et de Bk dans l'expression précédente?
Merci
Est-ce que la propriété "conditionnellement indépendante" est vérifiée si :
P( A intersection Bk) = P( A intersection B1) * P( A intersection B2) * ... * P( A intersection Bn) ???
Ou bien faut-il inverser les rôles de A et de Bk dans l'expression précédente?
Merci
15 messages
- Page 1 sur 1
Qui est en ligne
Utilisateurs parcourant ce forum : Aucun utilisateur enregistré et 24 invités
Tu pars déja ?
Fais toi aider gratuitement sur Maths-forum !
Créé un compte en 1 minute et pose ta question dans le forum ;-)
Identification
Pas encore inscrit ?
Ou identifiez-vous :