Bonsoir,
Je suis complètement perdu avec la sortie R. Je n ai pas pu assister au cours mais j ai essayé de trouver quelques tutoriels :résultats des centaines de pages pour apprendre à se servir du logiciel mais rien pour la simple "lecture" comme demandé dans l exercice ci joint. https://photos.app.goo.gl/Z2YtLcdcZDHdZ3nJ7
Pourriez vous me donner quelques indications ?
Merci d avance
Lecture d'une sortie R, statistiques
3 messages
- Page 1 sur 1
Re: Lecture d'une sortie R, statistiques
![]() par LB2 » 31 Mai 2019, 20:14
par LB2 » 31 Mai 2019, 20:14
Quelle question essaies tu de résoudre?
Les hypothèses sont : Les erreurs résiduelles sont indépendantes, de même loi, normale centrée et de variance
sont indépendantes, de même loi, normale centrée et de variance 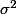 (homoscédasticité)
(homoscédasticité)
Les niveaux du facteur d'intérêt "département"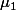 , ...,
, ..., 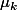 et la variance sont inconnus.
et la variance sont inconnus.
Je pense que dans R la variable DEP contient des variables "dummy" indiquant le département, donc k = 4 départements différents.
Il y a 3566 erreurs résiduelles, donc 3566 communes différentes.
Dans le test d'analyse de la variance, quelle est l'hypothèse nulle?
Quelle est l'hypothèse alternative?
Quelle est la statistique du test?
Voir ce document :
http://www.stat.yale.edu/Courses/1997-9 ... ovareg.htm
Les hypothèses sont : Les erreurs résiduelles
Les niveaux du facteur d'intérêt "département"
Je pense que dans R la variable DEP contient des variables "dummy" indiquant le département, donc k = 4 départements différents.
Il y a 3566 erreurs résiduelles, donc 3566 communes différentes.
Dans le test d'analyse de la variance, quelle est l'hypothèse nulle?
Quelle est l'hypothèse alternative?
Quelle est la statistique du test?
Voir ce document :
http://www.stat.yale.edu/Courses/1997-9 ... ovareg.htm
Re: Lecture d'une sortie R, statistiques
![]() par bargain99 » 04 Juin 2019, 17:18
par bargain99 » 04 Juin 2019, 17:18
Bonjour LB2 et merci de ta réponse. Je m'excuse du fait que la mienne soit aussi tardive, mais j'ai été sans internet quelques jours.
L'idée est que je n'arrive pas à comprendre ce que signifient les différents termes de cette sortie. J'ai essayé de chercher par moi même, mais juste pour " apprendre à lire" une sortie R, c est checher une aiguille dans une botte de foin. J ai lu ton lien, mais je ne suis pas tres bon en anglais et j ai du mal à comprendre.
Si tu veux bien, j ai quelques questions et ensuite j essaierais de répondre aux questions moi même.
Bon c est un tableau a double entrée non ? "DEP" signifie bien departement ? Mais que signifie le croisement avec Df, mean sq etc... ?
Je sais par exemple que mean sq est la déviation standard. Mais que cela signifie t il vis a vis de la variable "DEP" ?
Je ne comprends pas bien le role de "Résiduals", en quoi le nombre d"erreurs residuelles indiquerait le nombre de communes ? Et surtout qu est ce que tu entends par "erreurs résiduelles" ?
Voila désolé pour toutes ces questions, elle sont bateau j'imagine, mais je t'assure que c'est vraiment difficile d'en trouver la réponse seul sur internet.
-----
Pour en revenir aux questions que tu m'as posées, je dirais que Ho est l'hypothèse : le departement n'influence pas le revenu mediant des communes. Mais par contre je ne saurais pas dire pourquoi c est l'hypothèse la moins risquée. C est intuitif juste. H1 serait donc l.inverse.
Et pour la statistique du test, j en ai aucune idée. Jsui pas sur d'etre bien au point sur ce terme. Je dirais que c'est la moyenne des Y( i, l) non ?
Merci d avance
L'idée est que je n'arrive pas à comprendre ce que signifient les différents termes de cette sortie. J'ai essayé de chercher par moi même, mais juste pour " apprendre à lire" une sortie R, c est checher une aiguille dans une botte de foin. J ai lu ton lien, mais je ne suis pas tres bon en anglais et j ai du mal à comprendre.
Si tu veux bien, j ai quelques questions et ensuite j essaierais de répondre aux questions moi même.
Bon c est un tableau a double entrée non ? "DEP" signifie bien departement ? Mais que signifie le croisement avec Df, mean sq etc... ?
Je sais par exemple que mean sq est la déviation standard. Mais que cela signifie t il vis a vis de la variable "DEP" ?
Je ne comprends pas bien le role de "Résiduals", en quoi le nombre d"erreurs residuelles indiquerait le nombre de communes ? Et surtout qu est ce que tu entends par "erreurs résiduelles" ?
Voila désolé pour toutes ces questions, elle sont bateau j'imagine, mais je t'assure que c'est vraiment difficile d'en trouver la réponse seul sur internet.
-----
Pour en revenir aux questions que tu m'as posées, je dirais que Ho est l'hypothèse : le departement n'influence pas le revenu mediant des communes. Mais par contre je ne saurais pas dire pourquoi c est l'hypothèse la moins risquée. C est intuitif juste. H1 serait donc l.inverse.
Et pour la statistique du test, j en ai aucune idée. Jsui pas sur d'etre bien au point sur ce terme. Je dirais que c'est la moyenne des Y( i, l) non ?
Merci d avance
3 messages
- Page 1 sur 1
Qui est en ligne
Utilisateurs parcourant ce forum : Aucun utilisateur enregistré et 55 invités
Tu pars déja ?
Fais toi aider gratuitement sur Maths-forum !
Créé un compte en 1 minute et pose ta question dans le forum ;-)
Identification
Pas encore inscrit ?
Ou identifiez-vous :