Bonjour,
Je suis chercheur (M2 - stagiaire) en informatique, et ayant peu fait de maths ces dernières années, je bloque méchamment sur un problème qui pourrait vous sembler plus simple... Pour faire avancer la recherche, il faut de tout, et en l'occurence, c'est clairement un mathématicien qu'il nous faut ^.^
Pour ceux qui n'auraient pas le courage de tout lire, je résume le problème à résoudre à la fin (en espérant que ça corresponde réellement à ma situation ^^ )
Pour placer dans le contexte, je fais de la classification de données, et mon algo me permet à priori de résoudre tout type de problème avec une complexité de calcul relativement faible... Les données sont analysées sous formes de points dans un espace à n dimension (une dimension par attribut)
Pour cela je génère d'abord une première matrice carrée (/cubique/hypercubique...) pour "couvrir" toutes les données et regrouper un maximum de points dans les noeuds les plus proches. A partir de cette première matrice, j'arrive à repérer les coins les plus denses et commencer la recherche, puis je crée un sous-espace pour chaque groupe créé initialement (et donc une nouvelle matrice à n dimensions pour chacun) afin de diviser plus facilement les groupes pas assez "compacts"...
Mon premier problème: comment définir la taille de la matrice afin de pouvoir séparer efficacement la majorité des groupes à plus forte densité (avec certaines limites: aucun ordi ne peut stocker une matrice même vide de 15 noeuds sur 20 dimensions (pour le moment ^^) Inversement, avec 2 noeuds par dimensions on ne séparera jamais efficacement les données contenues... :mur: )
Deuxième problème: pour séparer les "sous-groupes" dans les sous-espaces, j'estime que deux noeuds de la matrice contenant des points sont ensemble s'il y a une distance inférieure à racine(nbDimensions) entre eux. (récursivement, on s'y retrouve). Pour chaque sous-espace, la matrice n'est plus carrée (/cubique...) car l'intervalle de données n'est pas forcément proportionnel à l'intervalle de l'ensemble initial pour chaque dimension. (difficile à expliquer... :hum: )
Pour le problème 1: le calcul standard utilisé dans mon domaine est totalement défaillant et je n'ai aucune idée de comment l'ajuster... (Matrice initialisée avec log_m(n) noeuds par dimension (m= nb dimensions , n=nb points)
Pour le problème 2: mon idée actuelle serait de calculer une distance moyenne entre les points en supposant qu'ils soient répartis équitablement. Puisqu'ils ne le seront évidemment pas, cela permettrait de déterminer pour chaque dimension la différence "d'intervalle" entre les points (par rapport aux autres dimensions), et je pourrais alors trouver des pondérations adéquates pour définir dans quelle dimension attribuer plus ou moins de noeuds, tout en gardant une moyenne définie par le problème 1...
Pour résumer, le problème (à moins que vous ayez une meilleure idée :id: ) serait de trouver la moyenne des distances entre un point et tout autre dans un espace à n dimensions, chaque dimension étalée sur un intervalle de valeurs défini... :hein:
Désolé si tout n'est pas très clair, durdur de résumer 3 mois de boulot en 20 lignes ^^'
Merci à ceux qui auront pris le temps de lire en tout cas :)
Challenge: définir la taille des n dimensions d'une matrice :)
17 messages
- Page 1 sur 1
![]() par Finrod » 25 Mai 2010, 17:54
par Finrod » 25 Mai 2010, 17:54
SI la répartition des points suit une loi uniforme alors il est possible de calculer la loi de probabilité de la distance entre deux points.
La loi de la distance moyenne entre deux points dans un système de n points sera par contre différentes et plus complexe, à cause de problème de dépendance.
De plus, ceci n'est pas valable si la position des points est censé dépendre du terrain. Tu ne nous as pas dit ce que tu modélisais, mais, pour donner un exemple ou ça marche pas, des insectes dans une boite ont tendance à se coller aux bords donc ne se répartissent pas suivant une loi uniforme.
Je pense que je saurais faire pour deux points sur une droite. Après c'est du costaud.
Peut être faire des statistiques serait-il plus avisé pour approximer cette distance moyenne. Il faudra juste alors calculer l'intervalle de confiance (C'est pas super fastoche non plus).
La loi de la distance moyenne entre deux points dans un système de n points sera par contre différentes et plus complexe, à cause de problème de dépendance.
De plus, ceci n'est pas valable si la position des points est censé dépendre du terrain. Tu ne nous as pas dit ce que tu modélisais, mais, pour donner un exemple ou ça marche pas, des insectes dans une boite ont tendance à se coller aux bords donc ne se répartissent pas suivant une loi uniforme.
Je pense que je saurais faire pour deux points sur une droite. Après c'est du costaud.
Peut être faire des statistiques serait-il plus avisé pour approximer cette distance moyenne. Il faudra juste alors calculer l'intervalle de confiance (C'est pas super fastoche non plus).
![]() par shito57 » 25 Mai 2010, 21:05
par shito57 » 25 Mai 2010, 21:05
A vrai dire, le but est de modéliser tout type de données:
Exemple classique: on relève sur des fleurs de 3 types différent la longueur et la largeur de leurs pétales et cépales, ce qui nous donne 4 attributs et donc 4 dimensions pour représenter chaque fleur observée. Il existe un jeu de données "classique" comportant 150 prélèvements (50 de chaque) et certains algos classiques peuvent identifier les groupes à environs 92% (2 groupes de points se "chevauchent" un peu, donc on est obligés d'en associer une partie au mauvais groupe)
Dans mon cas, on part de rien, mais avec une bonne matrice de "recouvrement" (j'ai testé avec différentes valeurs arbitraires, sans pouvoir généraliser) on peut obtenir d'excellents résultats dans la plupart des cas (répartition Gaussienne, ellipsoïdale, ou formes spéciales telles que des spirales ou cercles concentriques (en 2D), etc...)
Donc en admettant que la répartition des points suive une loi uniforme, on devrait pouvoir estimer un maillage correct pour repérer les groupes à partir des espaces blancs (noeuds vides de la matrice)
Justement, le but de mon travail (clustering) est de dissocier des données à partir... de rien :briques: Tout ce dont je dispose est l'ensemble des coordonnées des points. Introduire des stats reviendrait à inclure une connaissance, ce dont on ne dispose pas ^^'
Pour la génération de la matrice, j'ai pensé que ça pourrait être une idée de se représenter une répartition suivant une loi uniforme. Pour le reste du traitement,
Donc à partir de juste l'intervalle de chaque dimension et du nombre de points, trouver une distance moyenne (sur chaque dimension) serait trop complexe? A un moment j'avais pensé calculer séparément l'écart-type de chaque dimension mais ça me paraissait un peu bizarre et peut-être un peu lourd...
comprends pas... :hum:
Peut-être aussi que je prends mal le problème: on n'a aucune idée de l'échelle dans laquelle se positionner (on peut avoir des données de natures différentes donc des intervalles totalement différents d'une dimension à l'autre), on ne connait pas le type de répartition (Gauss, ellipse...), tout ce qu'on a c'est l'ensemble des points, desquels je récupère les valeurs min/max dans chaque dimension. (il est important de faire un minimum de lectures de la base de données, on peut avoir des milliards voire plus de données à traiter sur un plus ou moins grand nombre de dimensions, d'où ma recherche d'une formule mathématique efficace :happy2:
Exemple classique: on relève sur des fleurs de 3 types différent la longueur et la largeur de leurs pétales et cépales, ce qui nous donne 4 attributs et donc 4 dimensions pour représenter chaque fleur observée. Il existe un jeu de données "classique" comportant 150 prélèvements (50 de chaque) et certains algos classiques peuvent identifier les groupes à environs 92% (2 groupes de points se "chevauchent" un peu, donc on est obligés d'en associer une partie au mauvais groupe)
Dans mon cas, on part de rien, mais avec une bonne matrice de "recouvrement" (j'ai testé avec différentes valeurs arbitraires, sans pouvoir généraliser) on peut obtenir d'excellents résultats dans la plupart des cas (répartition Gaussienne, ellipsoïdale, ou formes spéciales telles que des spirales ou cercles concentriques (en 2D), etc...)
Donc en admettant que la répartition des points suive une loi uniforme, on devrait pouvoir estimer un maillage correct pour repérer les groupes à partir des espaces blancs (noeuds vides de la matrice)
Peut être faire des statistiques serait-il plus avisé pour approximer cette distance moyenne
Justement, le but de mon travail (clustering) est de dissocier des données à partir... de rien :briques: Tout ce dont je dispose est l'ensemble des coordonnées des points. Introduire des stats reviendrait à inclure une connaissance, ce dont on ne dispose pas ^^'
Si la répartition des points suit une loi uniforme alors il est possible de calculer la loi de probabilité de la distance entre deux points.
Pour la génération de la matrice, j'ai pensé que ça pourrait être une idée de se représenter une répartition suivant une loi uniforme. Pour le reste du traitement,
La loi de la distance moyenne entre deux points dans un système de n points sera par contre différentes et plus complexe, à cause de problème de dépendance.
Donc à partir de juste l'intervalle de chaque dimension et du nombre de points, trouver une distance moyenne (sur chaque dimension) serait trop complexe? A un moment j'avais pensé calculer séparément l'écart-type de chaque dimension mais ça me paraissait un peu bizarre et peut-être un peu lourd...
Je pense que je saurais faire pour deux points sur une droite. Après c'est du costaud.
comprends pas... :hum:
Peut-être aussi que je prends mal le problème: on n'a aucune idée de l'échelle dans laquelle se positionner (on peut avoir des données de natures différentes donc des intervalles totalement différents d'une dimension à l'autre), on ne connait pas le type de répartition (Gauss, ellipse...), tout ce qu'on a c'est l'ensemble des points, desquels je récupère les valeurs min/max dans chaque dimension. (il est important de faire un minimum de lectures de la base de données, on peut avoir des milliards voire plus de données à traiter sur un plus ou moins grand nombre de dimensions, d'où ma recherche d'une formule mathématique efficace :happy2:
![]() par shito57 » 27 Mai 2010, 05:55
par shito57 » 27 Mai 2010, 05:55
Pour résumer le problème principal, je pense que ce serait plus clair de l'énoncer comme suit: :)
Soient n points répartis sur un espace à m dimensions {d_0, d_1,...,d_(m-1)}.
Dans chaque dimension les valeurs sont réparties sur un intervalle différent, respectivement {i_0,i_1,...i_(m-1)}
La répartition des point est uniforme et puisque les données peuvent être de nature différente l'échelle n'a pas d'importance, on a autant de points dans chaque dimension.
Pour chacune des m dimensions, quelle serait la distance moyenne entre tout point de l'espace, sachant que la distance moyenne est la moyenne des distances entre chaque point
Exemple: sur 2 dimensions, 9 points: on a 3 points par dimension, mais des intervalles de valeurs différents. On cherche donc point chaque point la moyenne des distances à tous les autres points, puis on fait la moyenne de ces moyennes :happy2:
Soient n points répartis sur un espace à m dimensions {d_0, d_1,...,d_(m-1)}.
Dans chaque dimension les valeurs sont réparties sur un intervalle différent, respectivement {i_0,i_1,...i_(m-1)}
La répartition des point est uniforme et puisque les données peuvent être de nature différente l'échelle n'a pas d'importance, on a autant de points dans chaque dimension.
Pour chacune des m dimensions, quelle serait la distance moyenne entre tout point de l'espace, sachant que la distance moyenne est la moyenne des distances entre chaque point
Exemple: sur 2 dimensions, 9 points: on a 3 points par dimension, mais des intervalles de valeurs différents. On cherche donc point chaque point la moyenne des distances à tous les autres points, puis on fait la moyenne de ces moyennes :happy2:
![]() par Finrod » 27 Mai 2010, 07:16
par Finrod » 27 Mai 2010, 07:16
Houlà mais c'est quoi ta notion de dimension, je te suis plus.
Quand il y a m dimension, un point de l'espace à m coordonnées, mais je trouve bizarre de dire qu'il appartient à une dimension... (à moins qu'il soit sur un bord)
A mon avis, dans les phénomènes que tu vas modéliser, la répartition sera parfois uniforme et parfois pas du tout. Le plus général serait donc de supposer qu'elle suit une loi à densité.
Après, sur une dimension, S'il n'y a que deux données ça donne un truc du genre.
X et Y suivent une même loi de densité f sur [0,1]. Il faut calculer la loi du couple, puis la fonction de répartition de leur distance.
Je me demande si tu ne peux pas écrire une formule du genre (j'ai pas vérifié)
t+u)=\int_{0}^{t}P(Xt+u))
ou sinon il faut conditionner par X<Y et raisonner par symétrie.
A la limite tu peux essayer de faire ça pour n points. ça te donnera une distance moyenne entre les coordonnées de tes points dans l'espace pour chaque dimension.
Mais de là à en déduire la distance moyenne dans l'espace, pas si simple.
Enfin sauf cas particulier, il me semble que si les lois des coordonnées sont des gaussiennes de même paramètres (0,1) par exemple, la loi de la norme 2 est la racine d'une somme de n gaussiennes au carré, donc la racine d'un khi²(n). Il me semble que c'est une loi connue (peut être student ou autre, je me rappelle plus).
Donc déjà si tu sais faire le cas gaussiennes et le cas uniforme, c'est pas mal.
edit: pour la cas gaussien, on calcule directement la loi de la distance dans l'espace à n dimensions. Donc c'est peut être mieux de faire comme ça.
Quand il y a m dimension, un point de l'espace à m coordonnées, mais je trouve bizarre de dire qu'il appartient à une dimension... (à moins qu'il soit sur un bord)
A mon avis, dans les phénomènes que tu vas modéliser, la répartition sera parfois uniforme et parfois pas du tout. Le plus général serait donc de supposer qu'elle suit une loi à densité.
Après, sur une dimension, S'il n'y a que deux données ça donne un truc du genre.
X et Y suivent une même loi de densité f sur [0,1]. Il faut calculer la loi du couple, puis la fonction de répartition de leur distance.
Je me demande si tu ne peux pas écrire une formule du genre (j'ai pas vérifié)
ou sinon il faut conditionner par X<Y et raisonner par symétrie.
A la limite tu peux essayer de faire ça pour n points. ça te donnera une distance moyenne entre les coordonnées de tes points dans l'espace pour chaque dimension.
Mais de là à en déduire la distance moyenne dans l'espace, pas si simple.
Enfin sauf cas particulier, il me semble que si les lois des coordonnées sont des gaussiennes de même paramètres (0,1) par exemple, la loi de la norme 2 est la racine d'une somme de n gaussiennes au carré, donc la racine d'un khi²(n). Il me semble que c'est une loi connue (peut être student ou autre, je me rappelle plus).
Donc déjà si tu sais faire le cas gaussiennes et le cas uniforme, c'est pas mal.
edit: pour la cas gaussien, on calcule directement la loi de la distance dans l'espace à n dimensions. Donc c'est peut être mieux de faire comme ça.
![]() par shito57 » 27 Mai 2010, 08:46
par shito57 » 27 Mai 2010, 08:46
hum oui désolé je viens de me relire et j'ai vraiment écrit comme un chacal ^^'
Ce que je voulais dire par là c'est que si on se représente l'espace à 2 dimensions, on verra 3*3 points, avec des valeurs pouvant aller par exemple de 2 à 50 en x et de 0,5 à 0,7 en y. En gros si on projette les valeurs sur une seule dimension, on n'en aura que 3 différentes
Effectivement les données que je traite ne sont jamais uniforme, mais elle peut être Gaussienne, ellipsoïdale ou bien les données ne suivent aucune loi de proba. C'est pourquoi je suppose qu'on suit une loi uniforme afin de savoir comment placer les noeuds de ma "matrice de recouvrement des données". Alors les paquets de point seront séparés les uns des autres par les noeuds vides de cette matrice virtuelle. La distance moyenne dans chaque dimension me permet donc de générer cette matrice, de fait un quadrillage de l'ensemble des données afin de les classifier plus rapidement : j'associe à un noeud de la matrice tous les points les plus proches, et je classifie ensuite les noeuds au lieu de classifier les points. Au lieu de traiter 20 milliards de points, je vais donc peut-être traiter 50 000 noeuds...
Après, ça fait un bail que je n'ai pas touché aux lois de probas et je n'ai presque plus fait de maths depuis quelques années, donc j'ai du mal à me représenter le sens de ta formule et comment récupérer une distance moyenne avec... :-S (oui oui j'en suis à ce point... U.U' )
O.o Jamais entendu parler de ça...
Ce que je voulais dire par là c'est que si on se représente l'espace à 2 dimensions, on verra 3*3 points, avec des valeurs pouvant aller par exemple de 2 à 50 en x et de 0,5 à 0,7 en y. En gros si on projette les valeurs sur une seule dimension, on n'en aura que 3 différentes
Effectivement les données que je traite ne sont jamais uniforme, mais elle peut être Gaussienne, ellipsoïdale ou bien les données ne suivent aucune loi de proba. C'est pourquoi je suppose qu'on suit une loi uniforme afin de savoir comment placer les noeuds de ma "matrice de recouvrement des données". Alors les paquets de point seront séparés les uns des autres par les noeuds vides de cette matrice virtuelle. La distance moyenne dans chaque dimension me permet donc de générer cette matrice, de fait un quadrillage de l'ensemble des données afin de les classifier plus rapidement : j'associe à un noeud de la matrice tous les points les plus proches, et je classifie ensuite les noeuds au lieu de classifier les points. Au lieu de traiter 20 milliards de points, je vais donc peut-être traiter 50 000 noeuds...
Après, ça fait un bail que je n'ai pas touché aux lois de probas et je n'ai presque plus fait de maths depuis quelques années, donc j'ai du mal à me représenter le sens de ta formule et comment récupérer une distance moyenne avec... :-S (oui oui j'en suis à ce point... U.U' )
donc la racine d'un khi²(n)
O.o Jamais entendu parler de ça...
![]() par Finrod » 27 Mai 2010, 09:47
par Finrod » 27 Mai 2010, 09:47
ou bien les données ne suivent aucune loi de proba
Il existe toujours des loi de proba qui approximeront tes données. Dans certains cas, le seul moyen de les calculer es statistique donc interdit dans ton cas si je te suis.
regarde ici :
[url]http://fr.wikipedia.org/wiki/Loi_du_;)²[/url]
Donc à priori si les coordonnées sont gaussiennes, la distance au carré est une khi².
Après s'il y 2 points il faut faire la moyenne.
S'il y a n points, la distance moyenne change. Il faut calculer la loi de la somme des distance entre deux points, sachant qu'il n'y a pas indépendance...
Là ça devient trop dur pour moi qui ai arrêté les proba en BAC+5. Mais ça a pas l'air impossible, ça dépend à quel niveau tu es. Pour une thèse, c'est faisable, pour un mémoire de DEA, peut être aussi.
Une question stupide : Tes échantillons de données sont vraiment si limités que ça ? Car à la base, à partir d'un échantillons d'un trentaine de points, tu peux faire une estimation statistique de la loi de la distance moyenne...
Edit : Si tu as des milliard de points, comme je viens de le lire. Alors prendre un estimateur stat est possible, rapide et efficace. La question est de savoir si tu connais la théorie des estimateurs ?
![]() par shito57 » 27 Mai 2010, 12:59
par shito57 » 27 Mai 2010, 12:59
Oulà, alors non je n'ai aucune idée de la théorie des estimateurs...
Pour les échantillons, en fait je n'ai pas de données permettant [edit]d'établir une connaissance et de faire des stats pouvant être généralisées[/edit], mais j'ai toutes les coordonnées de tous les points à classer. Comme dit on ne peut pas toujours trouver de loi de répartition exacte, précisément, et surtout avec un temps de calcul acceptable, donc je tiens à rester sur le moins compliqué possible.
Après mon niveau, c'est master info mais avec trop peu de maths, là je finis bientôt mon stage et cette formule de distance moyenne c'est un peu la clé...
Pour les échantillons, en fait je n'ai pas de données permettant [edit]d'établir une connaissance et de faire des stats pouvant être généralisées[/edit], mais j'ai toutes les coordonnées de tous les points à classer. Comme dit on ne peut pas toujours trouver de loi de répartition exacte, précisément, et surtout avec un temps de calcul acceptable, donc je tiens à rester sur le moins compliqué possible.
Après mon niveau, c'est master info mais avec trop peu de maths, là je finis bientôt mon stage et cette formule de distance moyenne c'est un peu la clé...
![]() par Finrod » 27 Mai 2010, 13:15
par Finrod » 27 Mai 2010, 13:15
Alors il faut une astuce.
Tu n'as surement pas besoin de faire un calcul complet.
Si j'ai une idée, je la poste.
Tu n'as surement pas besoin de faire un calcul complet.
Si j'ai une idée, je la poste.
![]() par Finrod » 27 Mai 2010, 13:23
par Finrod » 27 Mai 2010, 13:23
Voilà une idée con.
Si tu as une loi uniforme, qui est le pire des cas pour les distances moyenne alors tu connais la concentration de points dans chaque zone, qui est proportionnelle à la taille de la zone.
Donc mettons que tu découpe ton hypercube en petits hypercube égaux. LA concentration de point sera la même dans chaque.
Pour n points, si tu découpe chaque dimension k fois, i.e. l'hypercube (dimension m) est découpé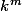 fois tu as une concentration de
fois tu as une concentration de
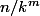 points par petit hypercube.
points par petit hypercube.
Donc si tu veux que ton nombre de point par petit cube soit autour de 1, il faux fixer k tel que ce rapport ou m et n sont déterminés soit proche de 1. Si tu veux qu'il soit proche de 100 (tu as parlé de paquets), tu fixes k pour que le rapport soit proche de 100.
ainsi de suite.
ps: j'ai peut être pas tout compris à l'histoire des noeuds...
edit : et si tu connais un peu la répartition à l'avance et qu'elle est loi d'être uniforme, il y aura des paquets plus gros que prévu et des zones vide pour lesquels il faudra ajuster
Si tu as une loi uniforme, qui est le pire des cas pour les distances moyenne alors tu connais la concentration de points dans chaque zone, qui est proportionnelle à la taille de la zone.
Donc mettons que tu découpe ton hypercube en petits hypercube égaux. LA concentration de point sera la même dans chaque.
Pour n points, si tu découpe chaque dimension k fois, i.e. l'hypercube (dimension m) est découpé
Donc si tu veux que ton nombre de point par petit cube soit autour de 1, il faux fixer k tel que ce rapport ou m et n sont déterminés soit proche de 1. Si tu veux qu'il soit proche de 100 (tu as parlé de paquets), tu fixes k pour que le rapport soit proche de 100.
ainsi de suite.
ps: j'ai peut être pas tout compris à l'histoire des noeuds...
edit : et si tu connais un peu la répartition à l'avance et qu'elle est loi d'être uniforme, il y aura des paquets plus gros que prévu et des zones vide pour lesquels il faudra ajuster
![]() par shito57 » 29 Mai 2010, 10:56
par shito57 » 29 Mai 2010, 10:56
effectivement onn'aura jamais de répartition uniforme, c'est juste une idée que j'avais eue pour générer ma matrice avec un point par noeud en moyenne. Sachant que ce cas n'arrivera jamais, ça pouvait laisser assez d'espace entre les groupes pour les séparer. (les derniers tests prouvent que ce n'est pas troujours suffisant en fait :-/ )
Comme tu dis, après ça dépend combien je veux de points par noeud, mais ça dépend de la densité des points dans chaque groupe, et ça on n'en a aucune idée. Admettons qu'on ait une forte densité, ça ne servira à rien de faire une matrice avec en moyenne un point par noeud car on aura une très grande quantité de noeuds vides. Inversement, si les densités sont relativement faibles, il faudra impérativement avoir assez de noeuds pour pouvoir dissocier les groupes par la suite (sinon on ne trouvera pas de noeuds vides.
à priori, je pense que tu as bien saisi pour les noeuds
Non non, c'est l'idée, on n'en sait rien du tout
au final, tu m'as donné une idée:
1) Chercher la densité de pts par noeud souhaitée, (disons D) en fonction de la compacité du jeu de données... dont on n'a aucune idée... Peut-être en l'approximant avec l'éloignement moyen des points à la moyenne (écart-type?) ou bien calculer la distance moyenne entre tous les points deux à deux -> si c'est possible avec une formule générale, sans calculer toutes les distances entre 2 pts... :hum:
2) Reprendre une bête formule pour trouver k en fonction de D, du style racine m-ième de (n/D)
Comme tu dis, après ça dépend combien je veux de points par noeud, mais ça dépend de la densité des points dans chaque groupe, et ça on n'en a aucune idée. Admettons qu'on ait une forte densité, ça ne servira à rien de faire une matrice avec en moyenne un point par noeud car on aura une très grande quantité de noeuds vides. Inversement, si les densités sont relativement faibles, il faudra impérativement avoir assez de noeuds pour pouvoir dissocier les groupes par la suite (sinon on ne trouvera pas de noeuds vides.
à priori, je pense que tu as bien saisi pour les noeuds
edit : et si tu connais un peu la répartition à l'avance et qu'elle est loi d'être uniforme, il y aura des paquets plus gros que prévu et des zones vide pour lesquels il faudra ajuster
Non non, c'est l'idée, on n'en sait rien du tout
au final, tu m'as donné une idée:
1) Chercher la densité de pts par noeud souhaitée, (disons D) en fonction de la compacité du jeu de données... dont on n'a aucune idée... Peut-être en l'approximant avec l'éloignement moyen des points à la moyenne (écart-type?) ou bien calculer la distance moyenne entre tous les points deux à deux -> si c'est possible avec une formule générale, sans calculer toutes les distances entre 2 pts... :hum:
2) Reprendre une bête formule pour trouver k en fonction de D, du style racine m-ième de (n/D)
![]() par Finrod » 29 Mai 2010, 13:25
par Finrod » 29 Mai 2010, 13:25
Admettons qu'on ait une forte densité, ça ne servira à rien de faire une matrice avec en moyenne un point par noeud car on aura une très grande quantité de noeuds vides. Inversement, si les densités sont relativement faibles, il faudra impérativement avoir assez de noeuds pour pouvoir dissocier les groupes par la suite (sinon on ne trouvera pas de noeuds vides.
Houlà tu raisonne à l'envers là. Forte densité = peu de noeuds vides et faible l'inverse. Logique ça dépend du nombre de points.
De, plus il y a un autre facteur, plus important : Fort écart relatif de densité = + noeuds vides. Et faible = - noeuds vides.
Implémenter un programme qui repère les paquets de points pourrait être pas mal.
![]() par shito57 » 29 Mai 2010, 20:01
par shito57 » 29 Mai 2010, 20:01
Implémenter un programme qui repère les paquets de points pourrait être pas mal.
Haha oui c'est justement le but demon programme
et pour la logique de la densité, non justement c'est bien comme je le dis
C'est justement toute l'idée pour repérer les groupes de points: trouver les espaces vides autour de chaque bloc de points
![]() par Finrod » 29 Mai 2010, 21:13
par Finrod » 29 Mai 2010, 21:13
En pratique, Vide va devenir "avec un densité très faible", inférieure à un seuil donné je suppose.
![]() par shito57 » 29 Mai 2010, 22:31
par shito57 » 29 Mai 2010, 22:31
tout dépend de la densité de chaque groupe, et justement ce que je charche à faire, c'est m'assurer d'avoir ces noeuds vides pour séparer les groupes, d'où la recherche d'un maillage assez large.
![]() par Finrod » 30 Mai 2010, 11:33
par Finrod » 30 Mai 2010, 11:33
C'est pas faux.
Reste que il peut ne pas y avoir assez de vrai trous pour un maillage donné. Par exemple si la répartition par paquet correspond en fait à des zones denses et des zones plus clairsemés.
Auquel cas, il faut resserrer le maillage. Mais c'est le pire cas envisageable. Je ne pense pas qu'il soit de toute façon possible d'écrire un programme qui ai 100% de réussite. S'il permet de traiter des cas pratiques génériques, c'est bon.
Reste que il peut ne pas y avoir assez de vrai trous pour un maillage donné. Par exemple si la répartition par paquet correspond en fait à des zones denses et des zones plus clairsemés.
Auquel cas, il faut resserrer le maillage. Mais c'est le pire cas envisageable. Je ne pense pas qu'il soit de toute façon possible d'écrire un programme qui ai 100% de réussite. S'il permet de traiter des cas pratiques génériques, c'est bon.
![]() par shito57 » 30 Mai 2010, 11:51
par shito57 » 30 Mai 2010, 11:51
non justement, dans le cas de répartitions de densités différentes, je résous aussi le problème en fusionnant les groupes trouvés en fonction de la proximité jusqu'à obtenir le nombre de groupes souhaités.
100% c'est une utopie, mais mon but est de traiter au moins 80% des problèmes pouvant être résolus :)
100% c'est une utopie, mais mon but est de traiter au moins 80% des problèmes pouvant être résolus :)
17 messages
- Page 1 sur 1
Qui est en ligne
Utilisateurs parcourant ce forum : Aucun utilisateur enregistré et 53 invités
Tu pars déja ?
Fais toi aider gratuitement sur Maths-forum !
Créé un compte en 1 minute et pose ta question dans le forum ;-)
Identification
Pas encore inscrit ?
Ou identifiez-vous :