étude variance
13 messages
- Page 1 sur 1
étude variance
![]() par lunaa21 » 17 Aoû 2009, 14:07
par lunaa21 » 17 Aoû 2009, 14:07
bojour je suis toute nouvelle sur le forum. je dois fournir à l'entreprise dans laquelle je suis en stage une étude de variance sur différents critères, le problème est que je n'ai jamais fait cela. Pourriez vous me donnez des pistes de recherches.
![]() par maturin » 17 Aoû 2009, 15:30
par maturin » 17 Aoû 2009, 15:30
alors si tu veux la définition de la variance tu peux regrder sur wikipedia:
http://fr.wikipedia.org/wiki/Variance_(statistiques_et_probabilit%C3%A9s)
Maintenance un étude de variance dans une entreprise ça veut pas dire grand chose.
Donne nous plus d'info, te demande-t-on une étude mathématique ou juste trouver des belles phrases ?
La variance c'est ce qui explique l'écart des résultats avec la moyenne. Plus tu as des résultats loin de ce que tu attends plus la variance est grande.
http://fr.wikipedia.org/wiki/Variance_(statistiques_et_probabilit%C3%A9s)
Maintenance un étude de variance dans une entreprise ça veut pas dire grand chose.
Donne nous plus d'info, te demande-t-on une étude mathématique ou juste trouver des belles phrases ?
La variance c'est ce qui explique l'écart des résultats avec la moyenne. Plus tu as des résultats loin de ce que tu attends plus la variance est grande.
![]() par busard_des_roseaux » 17 Aoû 2009, 15:49
par busard_des_roseaux » 17 Aoû 2009, 15:49
bonjour,
tu peux aussi regarder des thèmes connexes comme:
- coefficient de corrélation de deux variables statistiques
- droite des moindres carrés
tu peux aussi regarder des thèmes connexes comme:
- coefficient de corrélation de deux variables statistiques
- droite des moindres carrés
![]() par lunaa21 » 18 Aoû 2009, 05:32
par lunaa21 » 18 Aoû 2009, 05:32
on me demande plus une étude mathématiques sur des résultats d'analyses que j'ai effectué
![]() par busard_des_roseaux » 18 Aoû 2009, 06:05
par busard_des_roseaux » 18 Aoû 2009, 06:05
![]() par lunaa21 » 18 Aoû 2009, 06:52
par lunaa21 » 18 Aoû 2009, 06:52
Ok je comprend mieux pourquoi je ne connait pas je viens tout juste de finir ma première année de BTS
![]() par sky-mars » 18 Aoû 2009, 08:31
par sky-mars » 18 Aoû 2009, 08:31
Salut
Elle doit donc faire une modélisation ^^ donc admettons que se soit une loi normale, elle doit déterminer sigma et m avec le plus petit biais possible c'est ca ?
Elle doit donc faire une modélisation ^^ donc admettons que se soit une loi normale, elle doit déterminer sigma et m avec le plus petit biais possible c'est ca ?
![]() par lunaa21 » 18 Aoû 2009, 11:52
par lunaa21 » 18 Aoû 2009, 11:52
sky-mars a écrit:Salut
Elle doit donc faire une modélisation ^^
salut tu pourrais m'expliquer ce que tu entends par modélisation?
et pourriez-vous m'expliquer la Loi du khi² je ne comprend rien à ce que j'ai lu sur internet? merci.
![]() par busard_des_roseaux » 18 Aoû 2009, 12:38
par busard_des_roseaux » 18 Aoû 2009, 12:38
salut,
on est en plein mois d'août,les matheux randonnent sur les GR et la ressource
se fait rare. voilà quelques explications sur les statistiques mais je n'y connais rien. :hum:
A priori, tu dispose d'une base de données avec des millions de données numériques et ces données suivent nécéssairement une loi (de proba).
En effet, une probgabilité est une mesure.elle permet de connaitre
de manière probabiliste,ie, statistique, la répartition des données.
Comme les données sont nombreuses, on considère un échantillon.
Disons de 100 valeurs. Ces valeurs sont interprétées comme des valeurs prises
par 100 variables aléatoires indépendantes de même loi. (qui est la loi de proba
des données).
Le modèle statistique standard est celui d'une famille de probabilités , indicées ou indéxées par un paramètre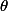 .
.
Grace à ce modèle, on peut trouver la loi de l'échantillon
et construire un estimateur. Je ne sais pas exactement ce que c'est, mais un estimateur permet, au vû d'un échantillon, de savoir si les données sont réparties selon une courbe en cloche (une gaussienne,etc..)
Ensuite, il me semble qu'avec un estimateur et un échantillon, on peut tester
la vraisemblance que l'ensemble des données suive telle ou telle loi.
on parle d'estimateurs avec biais (ils déforment tjrs l'estimation dans le même sens) ou sans biais.
Sans doute que les différents tests, adaptés aux différentes lois de probabilités, portent des noms différents.
en espérant ne pas avoir écrit trop de bêtises...
on est en plein mois d'août,les matheux randonnent sur les GR et la ressource
se fait rare. voilà quelques explications sur les statistiques mais je n'y connais rien. :hum:
A priori, tu dispose d'une base de données avec des millions de données numériques et ces données suivent nécéssairement une loi (de proba).
En effet, une probgabilité est une mesure.elle permet de connaitre
de manière probabiliste,ie, statistique, la répartition des données.
Comme les données sont nombreuses, on considère un échantillon.
Disons de 100 valeurs. Ces valeurs sont interprétées comme des valeurs prises
par 100 variables aléatoires indépendantes de même loi. (qui est la loi de proba
des données).
Le modèle statistique standard est celui d'une famille de probabilités , indicées ou indéxées par un paramètre
Grace à ce modèle, on peut trouver la loi de l'échantillon
et construire un estimateur. Je ne sais pas exactement ce que c'est, mais un estimateur permet, au vû d'un échantillon, de savoir si les données sont réparties selon une courbe en cloche (une gaussienne,etc..)
Ensuite, il me semble qu'avec un estimateur et un échantillon, on peut tester
la vraisemblance que l'ensemble des données suive telle ou telle loi.
on parle d'estimateurs avec biais (ils déforment tjrs l'estimation dans le même sens) ou sans biais.
Sans doute que les différents tests, adaptés aux différentes lois de probabilités, portent des noms différents.
en espérant ne pas avoir écrit trop de bêtises...
![]() par lunaa21 » 18 Aoû 2009, 12:52
par lunaa21 » 18 Aoû 2009, 12:52
si je comprend bien, les estimateurs sont reliés aux intervalles de confiance, ça ne rejoindrais pas la loi de Student par hasard ?
![]() par sky-mars » 18 Aoû 2009, 13:06
par sky-mars » 18 Aoû 2009, 13:06
Chaque estimateur pour une variable , la loi de Student c'est une autre chose .
Si par exemple tu cherche à vérifier une loi Normal (S,m)
tu cherche
S avec un estimateur avec le plus petit biais possible
idem avec m
Par exemple
un estimateur sans biais de m serait
}{p})
serait le meilleur moyen de calculer la moyenne
idem pour S tu cherche un estimateur genre la somme des (m-xi)^2 ou un truc qui tourne vers ca
Si par exemple tu cherche à vérifier une loi Normal (S,m)
tu cherche
S avec un estimateur avec le plus petit biais possible
idem avec m
Par exemple
un estimateur sans biais de m serait
serait le meilleur moyen de calculer la moyenne
idem pour S tu cherche un estimateur genre la somme des (m-xi)^2 ou un truc qui tourne vers ca
![]() par lunaa21 » 18 Aoû 2009, 13:15
par lunaa21 » 18 Aoû 2009, 13:15
sky-mars a écrit:Chaque estimateur pour une variable , la loi de Student c'est une autre chose .
Si par exemple tu cherche à vérifier une loi Normal (S,m)
tu cherche
S avec un estimateur avec le plus petit biais possible
idem avec m
Par exemple
un estimateur sans biais de m serait
serait le meilleur moyen de calculer la moyenne
idem pour S tu cherche un estimateur genre la somme des (m-xi)^2 ou un truc qui tourne vers ca
ok mes séries statistiques sont des séries continues de 8 à 16 échantillons (je ne peux pas faire plus d'analyses, mon stage est bientot fini), comment est-ce que je dois procéder ?
![]() par sky-mars » 18 Aoû 2009, 13:19
par sky-mars » 18 Aoû 2009, 13:19
tu n'a pas besoin de tout ça déjà, classe le genre, la population dans un tableau excel.
Ensuite tu vois quel loi tu peux modéliser, tente la plus classique la loi normale.
tu cherche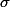 et m
et m
Pour m c'est facile un estimateur de la moyenne c'est la formule que j'ai mis avant.
Pour, je m'en rappel plus mdr, faudrait que je consulte mes cours
Tu fais tous tes calculs sous excel pour que sa aille très très vite, ensuite tu vois si tu obtiens une loi une normale ou non .
Si c'est pas le cas tu revérifie les calculs très rapidement, et si tu ne conclus pas tu passe à une autre loi, tu passe à la -2 par exemple et idem tu cherche les paramètres liées à cette loi et rebelotte
-2 par exemple et idem tu cherche les paramètres liées à cette loi et rebelotte
Je pense que j'aurai fait tout ça !
Avis des autres ?
Ensuite tu vois quel loi tu peux modéliser, tente la plus classique la loi normale.
tu cherche
Pour m c'est facile un estimateur de la moyenne c'est la formule que j'ai mis avant.
Pour
Tu fais tous tes calculs sous excel pour que sa aille très très vite, ensuite tu vois si tu obtiens une loi une normale ou non .
Si c'est pas le cas tu revérifie les calculs très rapidement, et si tu ne conclus pas tu passe à une autre loi, tu passe à la
Je pense que j'aurai fait tout ça !
Avis des autres ?
13 messages
- Page 1 sur 1
Qui est en ligne
Utilisateurs parcourant ce forum : Aucun utilisateur enregistré et 21 invités
Tu pars déja ?
Fais toi aider gratuitement sur Maths-forum !
Créé un compte en 1 minute et pose ta question dans le forum ;-)
Identification
Pas encore inscrit ?
Ou identifiez-vous :