Bjr,
V(x) serait donc = à E[(x-E(x))^2], je saisis l'intérieur de la formule calquée sur l'espérance des probabilités discrètes, en revanche, je ne capte pas la "remise" du E devant, on sait que V(x)=1 mais j'voulais gratter un ptit peu plus si vous voyez c'que je veux dire; merci d'avance de vos réponses.
Sur la Variance dans la loi normale centrée réduite
6 messages
- Page 1 sur 1

Re: Sur la Variance dans la loi normale centrée réduite
![]() par Ben314 » 12 Fév 2017, 12:45
par Ben314 » 12 Fév 2017, 12:45
Salut,
Dans ce type de formules, le x il représente une variable aléatoire réelle, c'est à dire un "truc" (*) qui peut prendre des tas de valeurs différentes avec des proba. données. Par exemple, x c'est le résultat du jet d'un dés : 6 valeurs possibles 1 ; 2 ; 3 ; 4 ; 5 ; 6 avec équiprobabilité.
Alors que E(x) lui, c'est une unique valeur qui, intuitivement parlant "résume" l'ensemble des valeur que peut prendre x. Dans le cas du dés, E(x)=3,5.
Ensuite, le x-E(x) il mesure l'écart qu'il y a entre LES (pluriel) valeurs que prend x et LA (singulier) moyenne E(x), donc c'est de nouveau un "truc" qui prend des tas de valeurs et c'est pas un nombre.
Par exemple, pour le dés, x-E(x) ça a de nouveau 6 valeur possible -2,5 ; -1,5 ; -0,5 ; +0,5 ; +1,5 ; +2,5 (avec équiprobabilité)
Si on calcule l'espérance E(x-E(x)) de cette nouvelle variable aléatoire, ça fait forcément zéro (dans tout les cas) vu que les négatifs "compensent exactement" les positifs. Arrivé à ce point là, intuitivement parlant, on se dit qu'un truc qui serait pas con, c'est de calculer non pas la moyenne des x-E(x), mais celle des |x-E(x)| qui donne l'écart en valeur absolue avec la moyenne et qui va permettre d'avoir une idée de si les x sont en général plutôt proche de la moyenne ou loin de la moyenne. Ca conduirait donc à calculer E(|x-E(x)|) c'est à dire dans le cas des dés, l'espérance de la variable aléatoire prenant les valeurs +2,5 ; +1,5 ; +0,5 ; +0,5 ; +1,5 ; +2,5 et ça donnerais le nombre 1,5.
Sauf qu'au niveau des calculs mathématiques (et de la théorie), cette valeur absolue (indispensable pour ne pas obtenir systématiquement 0) elle fait c... : c'est pas une fonction facile à manipuler à cause des différent cas.
Donc pour ramener tout LES (pluriel) x-E(x) en positif, on prend plutôt leur carré (x-E(x))² [et on prendra ensuite la racine carré du résultat pour obtenir le truc appelé "l'écart type"]. Dans le cas des dés, (x-E(x))² c'est la variable aléatoire prenant les valeurs (-2,5)² ; (-1,5)² ; (-0,5)² ; (+0,5)² ; (+1,5)² ; (+2,5)² (avec équiprobabilité) et la moyenne de cette variable aléatoire, c'est E((x-E(x))²)=2,92.
Enfin, bref, face à ta question "à quoi sert le E qu'on met devant", ben la réponse c'est que x-E(x) et E(x-E(x)) c'est pas du tout du tout "de même nature" :
x-E(x) est un truc "pas mal compliqué" i.e. c'est long de décrire ce que c'est vu qu'il faut donner les différentes valeurs que ça peut prendre et les proba associées
Alors que E(x-E(x)) on peut pas faire plus simple : c'est un simple nombre.
P.S. : Et le E qu'on met devant le x-E(x) n'a absolument rien à voir avec le fait que ce soit des proba discrètes ou pas. C'est exactement la même formule dans les deux cas, la différence réside uniquement dans le façon dont on calcule les différents E(?) qui, au premier abord, peut sembler différente dans le cas discret et dans le cas continu (somme dans le cas discret et intégrale dans le cas continu)
(*) Je préfère pas trop rentrer dans les détails.
Ben en fait, non, je vois pas bien ce que tu veut dire...paroxystique33 a écrit:Bjr,
V(x) serait donc = à E[(x-E(x))^2], je saisis l'intérieur de la formule calquée sur l'espérance des probabilités discrètes, en revanche, je ne capte pas la "remise" du E devant, on sait que V(x)=1 mais j'voulais gratter un ptit peu plus si vous voyez c'que je veux dire; merci d'avance de vos réponses.
Dans ce type de formules, le x il représente une variable aléatoire réelle, c'est à dire un "truc" (*) qui peut prendre des tas de valeurs différentes avec des proba. données. Par exemple, x c'est le résultat du jet d'un dés : 6 valeurs possibles 1 ; 2 ; 3 ; 4 ; 5 ; 6 avec équiprobabilité.
Alors que E(x) lui, c'est une unique valeur qui, intuitivement parlant "résume" l'ensemble des valeur que peut prendre x. Dans le cas du dés, E(x)=3,5.
Ensuite, le x-E(x) il mesure l'écart qu'il y a entre LES (pluriel) valeurs que prend x et LA (singulier) moyenne E(x), donc c'est de nouveau un "truc" qui prend des tas de valeurs et c'est pas un nombre.
Par exemple, pour le dés, x-E(x) ça a de nouveau 6 valeur possible -2,5 ; -1,5 ; -0,5 ; +0,5 ; +1,5 ; +2,5 (avec équiprobabilité)
Si on calcule l'espérance E(x-E(x)) de cette nouvelle variable aléatoire, ça fait forcément zéro (dans tout les cas) vu que les négatifs "compensent exactement" les positifs. Arrivé à ce point là, intuitivement parlant, on se dit qu'un truc qui serait pas con, c'est de calculer non pas la moyenne des x-E(x), mais celle des |x-E(x)| qui donne l'écart en valeur absolue avec la moyenne et qui va permettre d'avoir une idée de si les x sont en général plutôt proche de la moyenne ou loin de la moyenne. Ca conduirait donc à calculer E(|x-E(x)|) c'est à dire dans le cas des dés, l'espérance de la variable aléatoire prenant les valeurs +2,5 ; +1,5 ; +0,5 ; +0,5 ; +1,5 ; +2,5 et ça donnerais le nombre 1,5.
Sauf qu'au niveau des calculs mathématiques (et de la théorie), cette valeur absolue (indispensable pour ne pas obtenir systématiquement 0) elle fait c... : c'est pas une fonction facile à manipuler à cause des différent cas.
Donc pour ramener tout LES (pluriel) x-E(x) en positif, on prend plutôt leur carré (x-E(x))² [et on prendra ensuite la racine carré du résultat pour obtenir le truc appelé "l'écart type"]. Dans le cas des dés, (x-E(x))² c'est la variable aléatoire prenant les valeurs (-2,5)² ; (-1,5)² ; (-0,5)² ; (+0,5)² ; (+1,5)² ; (+2,5)² (avec équiprobabilité) et la moyenne de cette variable aléatoire, c'est E((x-E(x))²)=2,92.
Enfin, bref, face à ta question "à quoi sert le E qu'on met devant", ben la réponse c'est que x-E(x) et E(x-E(x)) c'est pas du tout du tout "de même nature" :
x-E(x) est un truc "pas mal compliqué" i.e. c'est long de décrire ce que c'est vu qu'il faut donner les différentes valeurs que ça peut prendre et les proba associées
Alors que E(x-E(x)) on peut pas faire plus simple : c'est un simple nombre.
P.S. : Et le E qu'on met devant le x-E(x) n'a absolument rien à voir avec le fait que ce soit des proba discrètes ou pas. C'est exactement la même formule dans les deux cas, la différence réside uniquement dans le façon dont on calcule les différents E(?) qui, au premier abord, peut sembler différente dans le cas discret et dans le cas continu (somme dans le cas discret et intégrale dans le cas continu)
(*) Je préfère pas trop rentrer dans les détails.
Qui n'entend qu'un son n'entend qu'une sonnerie. Signé : Sonfucius
Re: Sur la Variance dans la loi normale centrée réduite
![]() par paroxystique33 » 12 Fév 2017, 15:06
par paroxystique33 » 12 Fév 2017, 15:06
C'est marrant, dans ta réponse, on ressent comme une mouche qui t'aurait piqué, au moins elle te permet de fournir une réponse fournie et détaillée et je t'en remercie, néanmoins j'aimerai rajouter quelques "trucs" comme tu dis, tu évoques la moyenne des carrés valant 2,92 sur ton exemple probabiliste des jeux de dés à raison de la valeur moyenne du dé (3,5) ainsi que leur équiprobabilité(1/6) brefons bref, comme tu l'as observé sur l'objet de ma question j'évoque la variance dans le cadre de la loi normale centrée réduite et on "doit" obtenir 1 comme résultat a chaque fois pour cette variance, j'ignore pas que les probabilités discrètes et de loi normale réduite sont différentes mais les manuels eux t'en font le comparatif: "De façon similaire au cas des variables aléatoires discrètes, on peut définir la variance et l'écart-type d'une variable aléatoire continue par les formules :V(X)=E(X2)−(E(X))2 σ(X)=V(X)"(stp, ne me rappelles pas que la formule de la variance présentée est le développement de notre formule sur la moyenne des carrées, merci! ![:]](https://www.maths-forum.com/images/smilies/8.gif "Dan.San") ) Donc en fait pourquoi 1? Est-cela le détail dont tu parlais?:
) Donc en fait pourquoi 1? Est-cela le détail dont tu parlais?:
) Donc en fait pourquoi 1? Est-cela le détail dont tu parlais?: - Variance_loi-normale-centrée-réduite-1.jpg (26.67 Kio) Vu 439 fois
Re: Sur la Variance dans la loi normale centrée réduite
![]() par Ben314 » 12 Fév 2017, 15:50
par Ben314 » 12 Fév 2017, 15:50
Non, le 1 dont tu parle, il a pas grand chose (pour ne pas dire rien du tout) a voir avec ma réponse du post précédent.
Comme d'hab. (voir le thread où je me fait archi-pourrir pour l'avoir déjà fait), je répond stricto senso à la question posée : "pourquoi met-on un E devant le (x-E(x))²" qui est le début de ta prose en ne comprenant pas bien le pourquoi tu parle ensuite de V(x)=1 dans le cas de la loi normale centrée réduite (donc je répond absolument pas à cette partie là et je le signale au début de ma réponse en disant que j'ai pas trop bien compris la question...).
Le 1 qui est le résultat du calcul de ton encadré, il provient... d'un calcul et c'est tout.
Ce calcul là montre que la loi de densité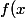\!=\!\frac{1}{\sqrt{2\pi}}\exp(-\frac{x^2}{2})) a une variance égale à 1 et il ne montre rien de plus (ni de moins...)
a une variance égale à 1 et il ne montre rien de plus (ni de moins...)
Après, le truc important, c'est de savoir que "dans la nature" (en math. est surtout dans des tas d'autres domaines que les maths.) on rencontre archi. fréquemment des variables aléatoire qui suivent des loi Gaussiennes (ou normales), mais par contre, avec des moyennes et des écart types absolument quelconque.
Sauf que le matheux, qui est un gros feignant, il a constaté que, partant de n'importe quelle loi gaussienne de moyenne et d'écart type quelconque, si on retranche la moyenne puis qu'on divise par l'écart type ben on tombe sur LA (unique) loi gaussienne "centrée réduite", c'est à dire de moyenne 0 et d'écart type 1.
Donc que c'était pas trop la peine de se faire c... à étudier de façon théorique TOUTES les loi gaussiennes vu qu'en étudiant uniquement celle centrée réduite, on en déduisait super rapidement le comportement des autres vu que c'est le même "à un facteur additif et multiplicatif prés".
Bref, à mon sens, c'est un peu (beaucoup) comme lorsque l'on étudie la "forme" des paraboles : vu qu'a un "décalage prés" elle se ramènent toutes à y=x², ben il suffit d'étudier proprement y=x² pour en déduire des tonnes de chose concernant toutes les paraboles. Idem pour les Hyperboles et le "modèle de base" y=1/x.
Dans les deux cas, les équations y=x² et y=1/x n'ont pas grand chose de particulier par rapport au cas général y=ax²+bx+c ou y=(ax+b)/(cx+d), à part qu'elle sont plus simple à écrire et que leurs "valeurs remarquables" (sommet, asymptote, etc..) sont évidement aussi plus simple à écrire.
Et comme elle "résument" très bien le cas général, ben c'est elle qu'on prend comme "modèle" du cas général (i.e. comme "fonction de référence")
Là, c'est pareil, LA loi Gaussienne centrée réduite, ben c'est "le modèle de référence" avec tout ce que ça sous entend...
Je sais pas si ça répond à ta question...
Comme d'hab. (voir le thread où je me fait archi-pourrir pour l'avoir déjà fait), je répond stricto senso à la question posée : "pourquoi met-on un E devant le (x-E(x))²" qui est le début de ta prose en ne comprenant pas bien le pourquoi tu parle ensuite de V(x)=1 dans le cas de la loi normale centrée réduite (donc je répond absolument pas à cette partie là et je le signale au début de ma réponse en disant que j'ai pas trop bien compris la question...).
Le 1 qui est le résultat du calcul de ton encadré, il provient... d'un calcul et c'est tout.
Ce calcul là montre que la loi de densité
Après, le truc important, c'est de savoir que "dans la nature" (en math. est surtout dans des tas d'autres domaines que les maths.) on rencontre archi. fréquemment des variables aléatoire qui suivent des loi Gaussiennes (ou normales), mais par contre, avec des moyennes et des écart types absolument quelconque.
Sauf que le matheux, qui est un gros feignant, il a constaté que, partant de n'importe quelle loi gaussienne de moyenne et d'écart type quelconque, si on retranche la moyenne puis qu'on divise par l'écart type ben on tombe sur LA (unique) loi gaussienne "centrée réduite", c'est à dire de moyenne 0 et d'écart type 1.
Donc que c'était pas trop la peine de se faire c... à étudier de façon théorique TOUTES les loi gaussiennes vu qu'en étudiant uniquement celle centrée réduite, on en déduisait super rapidement le comportement des autres vu que c'est le même "à un facteur additif et multiplicatif prés".
Bref, à mon sens, c'est un peu (beaucoup) comme lorsque l'on étudie la "forme" des paraboles : vu qu'a un "décalage prés" elle se ramènent toutes à y=x², ben il suffit d'étudier proprement y=x² pour en déduire des tonnes de chose concernant toutes les paraboles. Idem pour les Hyperboles et le "modèle de base" y=1/x.
Dans les deux cas, les équations y=x² et y=1/x n'ont pas grand chose de particulier par rapport au cas général y=ax²+bx+c ou y=(ax+b)/(cx+d), à part qu'elle sont plus simple à écrire et que leurs "valeurs remarquables" (sommet, asymptote, etc..) sont évidement aussi plus simple à écrire.
Et comme elle "résument" très bien le cas général, ben c'est elle qu'on prend comme "modèle" du cas général (i.e. comme "fonction de référence")
Là, c'est pareil, LA loi Gaussienne centrée réduite, ben c'est "le modèle de référence" avec tout ce que ça sous entend...
Je sais pas si ça répond à ta question...
Qui n'entend qu'un son n'entend qu'une sonnerie. Signé : Sonfucius
Re: Sur la Variance dans la loi normale centrée réduite
![]() par paroxystique33 » 12 Fév 2017, 21:26
par paroxystique33 » 12 Fév 2017, 21:26
Si je vois ce que tu veux dire, tu me parle d'arborescence du savoir , des cas généraux et des spécialités(qui apparemment ont l'air d'être ton "truc")
Re: Sur la Variance dans la loi normale centrée réduite
![]() par Ben314 » 12 Fév 2017, 21:33
par Ben314 » 12 Fév 2017, 21:33
Je pense pas que ce soit particulièrement "mon" truc, mais plutôt LE truc des sciences en général : si en biologie on a regroupée les différentes espèces en classes et sous classe, c'est pour pouvoir définir des traits communs aux différentes classes et mieux comprendre les liens (et différences) qu'il y avait entre eux.
De ce coté là, le moins qu'on puise dire, c'est qu'en math. ont a rien inventés du tout : on range, on classe, on étudie des cas particulier qui "résument" le cas général comme on le fait... absolument partout et tout le temps depuis que les science existent (donc au moins depuis les Grecs en Occident)
C'est exactement la même chose qu'en biologie où l'animal dont on connait le mieux les chromosomes, c'est la mouche du vinaigre (Drosophila melanogaster)
Et pourquoi ? Ben parce que le fonctionnement des chromosomes est (quasi) le même chez tout les animaux mais que les chromosomes de la mouche du vinaigre sont plus gros (donc plus facile à étudier) et que ça va légèrement plus vite (sic) d'avoir sous la main 10 générations successives de mouches que... 10 générations successives d'éléphants... (sans parler du fait que, le labo. pour "ranger" 10 générations de 1000 mouches c'est pas tout à fait le même que celui pour 10 générations de 1000 éléphants...)
A part ça, ben on s'en fout royalement de la mouche en elle même : c'est un "modèle simple" et c'est tout.
Pour la gaussienne centrée réduite, ben c'est exactement la même chose : elle est plus simple à étudier et suffisante vu que les autres c'est (quasi) pareil et qu'on sait parfaitement comment les résultat sur celle centré réduite se "transmettent" aux autres.
Et c'est bien évidement la même chose dans absolument toutes les science sans exceptions : essayer de ranger les trucs du "général" au "spécialisé" et étudier en détail quelques "cas spécifiques" pour en déduire si possible le cas général au au moins "les grandes lignes" du cas général.
De ce coté là, le moins qu'on puise dire, c'est qu'en math. ont a rien inventés du tout : on range, on classe, on étudie des cas particulier qui "résument" le cas général comme on le fait... absolument partout et tout le temps depuis que les science existent (donc au moins depuis les Grecs en Occident)
C'est exactement la même chose qu'en biologie où l'animal dont on connait le mieux les chromosomes, c'est la mouche du vinaigre (Drosophila melanogaster)
Et pourquoi ? Ben parce que le fonctionnement des chromosomes est (quasi) le même chez tout les animaux mais que les chromosomes de la mouche du vinaigre sont plus gros (donc plus facile à étudier) et que ça va légèrement plus vite (sic) d'avoir sous la main 10 générations successives de mouches que... 10 générations successives d'éléphants... (sans parler du fait que, le labo. pour "ranger" 10 générations de 1000 mouches c'est pas tout à fait le même que celui pour 10 générations de 1000 éléphants...)
A part ça, ben on s'en fout royalement de la mouche en elle même : c'est un "modèle simple" et c'est tout.
Pour la gaussienne centrée réduite, ben c'est exactement la même chose : elle est plus simple à étudier et suffisante vu que les autres c'est (quasi) pareil et qu'on sait parfaitement comment les résultat sur celle centré réduite se "transmettent" aux autres.
Et c'est bien évidement la même chose dans absolument toutes les science sans exceptions : essayer de ranger les trucs du "général" au "spécialisé" et étudier en détail quelques "cas spécifiques" pour en déduire si possible le cas général au au moins "les grandes lignes" du cas général.
Qui n'entend qu'un son n'entend qu'une sonnerie. Signé : Sonfucius
6 messages
- Page 1 sur 1
Qui est en ligne
Utilisateurs parcourant ce forum : Aucun utilisateur enregistré et 72 invités
Tu pars déja ?
Fais toi aider gratuitement sur Maths-forum !
Créé un compte en 1 minute et pose ta question dans le forum ;-)
Identification
Pas encore inscrit ?
Ou identifiez-vous :