Bonjour, je m'intéresse aux rudiments de la méthode de Monte Carlo.
Pour mémoire on utilise cette méthode :
on tire aléatoirement un grand nombre de couples x,y, (compris entre 0 et 1).
On compte ensuite tous les couples tels que x^2+y^2<1 c'est à dire tous les points étant dans un cercle de rayon 1.
Au final, la probabilité qu'un nombre soit dans le cercle est q/N ou q est le nombre des points effectivements comptés et N le nombre de couples qu'on a tiré.
D'un autre coté, analytiquement on voit que la probabilité pour qu'un point tiré alatoirement soit dans le cercle est pi/4 (rapport de l'aire du cercle sur celle du carré de coté 1), je peux donc calculer pi : pi= 4*q/N
Je met donc en oeuvre cette méthode grace au logiciel scilab (code ci joint) et je m'étonne du fait que avec 900000 points, la précision obtenue sur pi n'est que de 10^-4, alors qu'avec d'autres algo, avec un tel nombre d'itérations j'aurai déja dépassé la précision du pi enregistré dans mon logiciel !
Je me demande ce qui cloche donc dans ce programme, est ce que celà pourrait venir de la façon dont les nombres aléatoires sont tirés ?
Si quelqu'un veut en discuter il sera le bienvenu .
//------ ci joint le code source : utilisable directement avec scilab .
tic();
n=900000; //nb de tirages
q=0;
x=rand(n,2);
bool=(x(:,1)^2+x(:,2)^2)<1;
[poubelle,q]=size(find(bool));
est_pi=4*q/n;
t=toc();
printf("Simulation effectuee en %f secondes\n",t);
printf("Estimation de pi : %f\n",est_pi);
diff=est_pi-%pi;
printf("différence est_pi-PI= %f\n",diff);
Méthode de MonteCarlo
9 messages
- Page 1 sur 1

![]() par nuage » 27 Juil 2008, 18:39
par nuage » 27 Juil 2008, 18:39
Salut,
la précision que tu obtiens est étonnamment bonne :
Si on regarde les lois de probabilités en cause :
Le nombre de point dans le cercle suit une loi binomiale de paramètres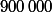 et
et 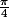 . Leur fréquence suit à peu près (c'est une très bonne approximation) une loi normale d'espérance et d'écart-type
. Leur fréquence suit à peu près (c'est une très bonne approximation) une loi normale d'espérance et d'écart-type }{900\,000}}\simeq 4,3\cdot10^{-4})
Donc au seuil de risque 5% tu ne peut guère espérer mieux qu'une précision de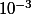
la précision que tu obtiens est étonnamment bonne :
Si on regarde les lois de probabilités en cause :
Le nombre de point dans le cercle suit une loi binomiale de paramètres
Donc au seuil de risque 5% tu ne peut guère espérer mieux qu'une précision de
![]() par vinch » 27 Juil 2008, 21:51
par vinch » 27 Juil 2008, 21:51
Je crois comprendre ton argument, c'est une fonction de deux variables, si je me déplace sur l'axe des x, la probabilité de trouver des points suit une loi binomiale, idem sur l'axe des y.
Par contre tu as l'air de faire un lien direct entre l'écart type et l'erreur que donne la méthode de monte carlo ici, je ne le comprends pas.
Mais j'essaye de m'imaginer un cas "idéal", imaginons que j'ai une quasi infinité de points, répartis uniformément dans mon carré, j'ai l'intuition que le rapport :
"nb de points dans le cercle sur nb de points total" me donnera pi/4 avec une précision bien meilleur que 10^-4 non ?
Je n'arrive pas à voir comment il pourrait y avoir une limite ici ...
Par contre tu as l'air de faire un lien direct entre l'écart type et l'erreur que donne la méthode de monte carlo ici, je ne le comprends pas.
Mais j'essaye de m'imaginer un cas "idéal", imaginons que j'ai une quasi infinité de points, répartis uniformément dans mon carré, j'ai l'intuition que le rapport :
"nb de points dans le cercle sur nb de points total" me donnera pi/4 avec une précision bien meilleur que 10^-4 non ?
Je n'arrive pas à voir comment il pourrait y avoir une limite ici ...
![]() par vinch » 27 Juil 2008, 22:53
par vinch » 27 Juil 2008, 22:53
après quelques calculs, je ne pense pas que la probabilité de trouver un point dans le cercle ou non suive une loi binomiale.
La probabilité pour un point d'être dans le cercle pour l'intervalle [x,x+dx] est p(x)=racine(1-x^2)
par contre si je fais l'intégrale entre -1 et 1 de p(x) je trouve pi/2, je n'arrive pas à retomber sur mon pi/4 ...
la discussion est toujours ouverte.
La probabilité pour un point d'être dans le cercle pour l'intervalle [x,x+dx] est p(x)=racine(1-x^2)
par contre si je fais l'intégrale entre -1 et 1 de p(x) je trouve pi/2, je n'arrive pas à retomber sur mon pi/4 ...
la discussion est toujours ouverte.
![]() par nuage » 27 Juil 2008, 22:57
par nuage » 27 Juil 2008, 22:57
Bien sur, si tu as une infinité de points (même dénombrable, je pense) le rapport sera .
Mais tu n'a pas une infinité de points (même pour un ordinateur très puissant, l'infini, même dénombrable, est loin).
Ton programme fait, en principe la chose suivante :
tirer un point au hasard, avec une répartition uniforme dans le carré (0,0)(1,0)(1,1)(0,1), puis regarder si il est dans le quart de cercle de centre (0,0) et de rayon 1.
Et il fait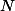 tirages indépendants (du moins on peut l'espérer) de ce type.
tirages indépendants (du moins on peut l'espérer) de ce type.
On considère alors la variable aléatoire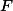 qui donne la proportion des tirages tombant dans le cercle. Si est assez grand (en général on considère que
qui donne la proportion des tirages tombant dans le cercle. Si est assez grand (en général on considère que 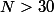 suffit) alors la loi de est proche d'une loi normale. Pour
suffit) alors la loi de est proche d'une loi normale. Pour 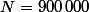 c'est exact avec une précision supérieur à
c'est exact avec une précision supérieur à 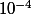 .
.
On étudie alors la probabilité pour que s'éloigne de son espérance (ici ) d'une quantité donné.
Pour des calculs précis je te renvoie à n'importe quel cours de stats.
Si on fait les choses à la louche il y a une proba de 5% d'avoir une erreur supérieure à 2 écart-type.
Or l'écart-type est égal à}{N}}) ce qui fait environ
ce qui fait environ 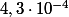 pour
pour 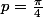 et sauf erreur de ma part. Donc une erreur vraisemblable de l'ordre de .
et sauf erreur de ma part. Donc une erreur vraisemblable de l'ordre de .
C'est une limitation lié à la méthode, pas au programme ou à l'ordinateur.
Mais tu n'a pas une infinité de points (même pour un ordinateur très puissant, l'infini, même dénombrable, est loin).
Ton programme fait, en principe la chose suivante :
tirer un point au hasard, avec une répartition uniforme dans le carré (0,0)(1,0)(1,1)(0,1), puis regarder si il est dans le quart de cercle de centre (0,0) et de rayon 1.
Et il fait
On considère alors la variable aléatoire
On étudie alors la probabilité pour que
Pour des calculs précis je te renvoie à n'importe quel cours de stats.
Si on fait les choses à la louche il y a une proba de 5% d'avoir une erreur supérieure à 2 écart-type.
Or l'écart-type est égal à
C'est une limitation lié à la méthode, pas au programme ou à l'ordinateur.
![]() par nuage » 27 Juil 2008, 23:55
par nuage » 27 Juil 2008, 23:55
Salut, nos messages se sont croisés.
Je crois que tu as une mauvaise interprétation, et que, peut-être, tu ne sais pas ce qu'est une loi binomiale.
Pour présenter la méthode de Monte Carlo dans ce cas particulier :
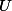 qui est la somme de variables aléatoires de Bernoulli indépendantes et de même paramètre. Ce nombre suit donc une loi binomiale de paramètres et
qui est la somme de variables aléatoires de Bernoulli indépendantes et de même paramètre. Ce nombre suit donc une loi binomiale de paramètres et 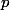
Quand est assez grand on approche cette loi par une loi normale.
Et en divisant par pour avoir la fréquence on obtient les résultats que j'ai donné. Sauf si je me suis trompé dans les calculs numériques, ce qui n'a rien d'invraisemblable.
vinch a écrit:après quelques calculs, je ne pense pas que la probabilité de trouver un point dans le cercle ou non suive une loi binomiale.
La probabilité pour un point d'être dans le cercle pour l'intervalle [x,x+dx] est p(x)=racine(1-x^2)
par contre si je fais l'intégrale entre -1 et 1 de p(x) je trouve pi/2, je n'arrive pas à retomber sur mon pi/4 ...
la discussion est toujours ouverte.
Je crois que tu as une mauvaise interprétation, et que, peut-être, tu ne sais pas ce qu'est une loi binomiale.
Pour présenter la méthode de Monte Carlo dans ce cas particulier :
- on a un morceau de plan
- on tire au hasard et uniformément
- la probabilité pour que le point soit dans
(intégrale de Lebesque, mais aussi n'importe quelle définition raisonnable de l'aire et des probabilités)
- les tirages sont indépendants (sinon on est vraiment dans la merde niveau calcul)
Quand
Et en divisant par
![]() par vinch » 28 Juil 2008, 10:01
par vinch » 28 Juil 2008, 10:01
Ok après quelques calculs et révision de mes cours de physique statistique je sors la tête du sceau.
Voila comment on peut interpreter, sans utiliser trop de résultats tout fait, la distribution de probabilité du nombre de points :
soit P(n) la probabilité d'avoir n points dans le cercle, pour avoir n points dans le cercle il faut 2 choses :
1) que n points soient tombés dans le cercle : proba=(pi/4)^n
2) ET que les autres soient tombés hors du cercle proba=(1-pi/4)^(N-n)
Comme les points sont indépendants et indiscernables on a N!/(n!*(N-n)!) façon d'y arriver.
Soit la probabilité d'avoir n points dans le cercle une loi binomiale tendant bien vers une gaussienne P(n) = N!/n!(N-n)! * (pi/4)^n*(1-pi/4)^N-n
Lorsqu'on trace ça avec un logiciel on a bien une loi normale centrée sur N*pi/4.
C'est dommage que l'écart type varie si doucement avec le nombre de points, on peut conclure que cette méthode est jolie, donne un bon petit aperçu du type de méthodes dites de Monte Carlo mais n'est pas efficace dans cet exemple précis (notamment à coté de méthode comme celle de Ramanujan qui donne 8 décimales à chaque itération ...)
Voila comment on peut interpreter, sans utiliser trop de résultats tout fait, la distribution de probabilité du nombre de points :
soit P(n) la probabilité d'avoir n points dans le cercle, pour avoir n points dans le cercle il faut 2 choses :
1) que n points soient tombés dans le cercle : proba=(pi/4)^n
2) ET que les autres soient tombés hors du cercle proba=(1-pi/4)^(N-n)
Comme les points sont indépendants et indiscernables on a N!/(n!*(N-n)!) façon d'y arriver.
Soit la probabilité d'avoir n points dans le cercle une loi binomiale tendant bien vers une gaussienne P(n) = N!/n!(N-n)! * (pi/4)^n*(1-pi/4)^N-n
Lorsqu'on trace ça avec un logiciel on a bien une loi normale centrée sur N*pi/4.
C'est dommage que l'écart type varie si doucement avec le nombre de points, on peut conclure que cette méthode est jolie, donne un bon petit aperçu du type de méthodes dites de Monte Carlo mais n'est pas efficace dans cet exemple précis (notamment à coté de méthode comme celle de Ramanujan qui donne 8 décimales à chaque itération ...)
Re:
![]() par IPCST » 18 Aoû 2008, 19:39
par IPCST » 18 Aoû 2008, 19:39
la convergence peut être améliorée !!!
regarde http://technoscience.org/rupp/ExercicesCorriges_Methodes_De_MonteCarlo.pdf
diverses techniques de Monte-Carlo
regarde http://technoscience.org/rupp/ExercicesCorriges_Methodes_De_MonteCarlo.pdf
diverses techniques de Monte-Carlo
![]() par magnolia86 » 18 Aoû 2008, 21:44
par magnolia86 » 18 Aoû 2008, 21:44
nuage a écrit:Mais tu n'a pas une infinité de points (même pour un ordinateur très puissant, l'infini, même dénombrable, est loin).
HS : l'infini, c'est long ! ...surtout à la fin... :we:
9 messages
- Page 1 sur 1
Qui est en ligne
Utilisateurs parcourant ce forum : Aucun utilisateur enregistré et 8 invités
Tu pars déja ?
Fais toi aider gratuitement sur Maths-forum !
Créé un compte en 1 minute et pose ta question dans le forum ;-)
Identification
Pas encore inscrit ?
Ou identifiez-vous :