Bonjour,
Je reviens sur ce forum qui m'a bien aidé par le passé, (moi qui suis un peu perdu en maths), pour vous exposer mon problème mathématique.
Je ne sais pas à quel niveau de difficulté il correspond, donc je l'ai placé dans la catégorie Défis et énigmes, s'il doit être déplacé n'hésitez pas.
Présentation :
Je travaille sur des combinaisons de longueur x et pouvant avoir entre 1 et y valeurs différentes.
J'ai réussi, en codant, à récupérer leurs différentes répartitions.
Ex : pour x=4, y=4, on aura donc 4 valeurs nommées ABCD, qui pourront donner des combinaisons avec les répartitions suivantes : 4000 (4 fois la même valeur donc soit AAAA, soit BBBB,etc.), 3100 (AAAB, AAAC,etc.), 2200, 2110, 1111
J'ai aussi réussi en codant à récupérer leur différentes distributions.
Ex :en ayant [A,B,C,D] pour référence, la répartition 3100 peut donner les distributions suivantes : [3,1,0,0], [3,0,1,0], [0,3,1,0], [0,0,1,3],etc.
Mon problème :
Je dois choisir une distribution et lui associer un nombre z entre 0 et y.
Ce nombre est le nombre de similitude qu'il peut avoir avec d'autres distributions.
Si je choisis une similitude de 2 pour la distribution [3,0,1,0] je dois trouver toutes les distributions qui ont deux valeurs en commun (identiques ou différentes), par exemple [1,0,1,2], [2,2,0,0],[1,1,1,1],etc.
Je cherche une fonction mathématique qui puisse, à partir d'une distribution ref et d'une similitude z, trouver toutes les distributions qui correspondent (et donc celles qui ne lui correspondent pas).
Pour l'instant je fais appel au calcul brut pour vérifier chaque distribution une par une mais ce n'est pas efficace, car en ayant cette fonction j'ai pour objectif de contrôler les différents paramètres de la fonction : les distributions correspondantes, la distribution ref et la similitude.
Si vous avez des pistes elles sont les bienvenues !
Combinaisons, répartitions, distributions, similitudes
36 messages
- Page 1 sur 2 - 1, 2
 Combinaisons, répartitions, distributions, similitudes
Combinaisons, répartitions, distributions, similitudes
![]() par Obwil » 05 Jan 2021, 19:26
par Obwil » 05 Jan 2021, 19:26
Modifié en dernier par Obwil le 05 Jan 2021, 22:17, modifié 1 fois.
Re: Combinaisons, répartitions, distributions, similitudes
![]() par GaBuZoMeu » 05 Jan 2021, 21:24
par GaBuZoMeu » 05 Jan 2021, 21:24
Bonsoir,
Je ne comprends pas ce que tu appelles "similitude". Je pensais qu'il s'agissait du nombre de places où figure le même nombre (genre MasterMind), mais ça ne colle pas avec tes exemples. Comment trouves-tu "une similitude de 2" entre [3,0,1,0] et [1,1,1,1] ???
Peux-tu être plus clair ?
Si je choisis une similitude de 2 pour la distribution [3,0,1,0] je dois trouver toutes les distributions qui ont deux distributions en commun, par exemple [1,0,1,2], [2,2,0,0],[1,1,1,1],etc.
Je ne comprends pas ce que tu appelles "similitude". Je pensais qu'il s'agissait du nombre de places où figure le même nombre (genre MasterMind), mais ça ne colle pas avec tes exemples. Comment trouves-tu "une similitude de 2" entre [3,0,1,0] et [1,1,1,1] ???
Peux-tu être plus clair ?
Re: Combinaisons, répartitions, distributions, similitudes
![]() par Obwil » 05 Jan 2021, 21:57
par Obwil » 05 Jan 2021, 21:57
GaBuZoMeu a écrit:Bonsoir,Si je choisis une similitude de 2 pour la distribution [3,0,1,0] je dois trouver toutes les distributions qui ont deux distributions en commun, par exemple [1,0,1,2], [2,2,0,0],[1,1,1,1],etc.
Je ne comprends pas ce que tu appelles "similitude". Je pensais qu'il s'agissait du nombre de places où figure le même nombre (genre MasterMind), mais ça ne colle pas avec tes exemples. Comment trouves-tu "une similitude de 2" entre [3,0,1,0] et [1,1,1,1] ???
Peux-tu être plus clair ?
Ah oui j'ai pas été suffisamment clair pardon.
La similitude c'est le nombre de valeurs communes entre les distributions, peu importe la position.
Pour [3,0,1,0] et [1,1,1,1] les deux similitudes sont [1,_,_,_] et [_,_,1,_].
Si on transpose avec les valeurs ABCD on a [3,0,1,0] = [A,A,A,C] et [1,1,1,1] = [A,B,C,D] donc les deux similitudes sont A et C.
Re: Combinaisons, répartitions, distributions, similitudes
![]() par GaBuZoMeu » 05 Jan 2021, 22:15
par GaBuZoMeu » 05 Jan 2021, 22:15
Ah, donc le nombre de similitudes entre 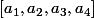 et
et 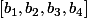 est la somme des
est la somme des ) ?
?
Re: Combinaisons, répartitions, distributions, similitudes
![]() par Obwil » 05 Jan 2021, 22:28
par Obwil » 05 Jan 2021, 22:28
GaBuZoMeu a écrit:Ah, donc le nombre de similitudes entre
Je ne comprends pas cette expression
Re: Combinaisons, répartitions, distributions, similitudes
![]() par GaBuZoMeu » 05 Jan 2021, 22:30
par GaBuZoMeu » 05 Jan 2021, 22:30
Le minimum de 3 et 1, c'est 1 ; le minimum de 0 et 1, c'est 0 ; le minimum de 1 et 1, c'est 1 ; le minimum de 1 et 0, c'est 0. La somme des minima est 2.
Je sors, bonne nuit !
Re: Combinaisons, répartitions, distributions, similitudes
![]() par Obwil » 05 Jan 2021, 22:38
par Obwil » 05 Jan 2021, 22:38
GaBuZoMeu a écrit:
Le minimum de 3 et 1, c'est 1 ; le minimum de 0 et 1, c'est 0 ; le minimum de 1 et 1, c'est 1 ; le minimum de 1 et 0, c'est 0. La somme des minima est 2.
Ah ok c'est intéressant lol je viens de découvrir un truc.
Du coup oui c'est exactement ça la similitude. Et dans mon code c'est ce que j'ai fait en plus.
Merci GaBuZoMeu A+
Re: Combinaisons, répartitions, distributions, similitudes
![]() par GaBuZoMeu » 06 Jan 2021, 14:26
par GaBuZoMeu » 06 Jan 2021, 14:26
Obwil a écrit:Je cherche une fonction mathématique qui puisse, à partir d'une distribution ref et d'une similitude z, trouver toutes les distributions qui correspondent (et donc celles qui ne lui correspondent pas).
Qu'appelles-tu "fonction mathématique" ?? Je ne vois pas autre chose qu'une procédure informatique pour faire ce travail. On peut chercher à l'optimiser.
Re: Combinaisons, répartitions, distributions, similitudes
![]() par Obwil » 06 Jan 2021, 19:06
par Obwil » 06 Jan 2021, 19:06
GaBuZoMeu a écrit:Qu'appelles-tu "fonction mathématique" ?? Je ne vois pas autre chose qu'une procédure informatique pour faire ce travail. On peut chercher à l'optimiser.
Je pensais à une fonction mathématique que j'utiliserais ensuite dans mon code donc on peut chercher directement via le code oui. Alors je ne sais coder qu'en PHP.
Voici ce que j'ai comme code pour l'instant :
- Code: Tout sélectionner
function SETsimilitudes_ttes_combi($combi_ref, $liste_distri, $simili_filtre = null){
// $combi_ref : la distribution ref
// $liste_distri : les distributions pour lesquelles on veut vérifier le nombre de similitudes avec la distribution ref
// $simili_filtre : si on veut chercher une similitude en particulier, et donc filtrer les distributions en fonction d'elle, on indique sa valeur
$similitudes_ttes_combi = [];
$combi_simili_filtre = [];
foreach($liste_distri as $key1 => $repartition){
foreach($repartition as $key2 => $combi){
$similitudes_ttes_combi[$key1][$key2] = 0;
foreach($combi as $key3 => $nb){
if($combi_ref[$key3] > 0 && $nb > 0){
if($combi_ref[$key3] <= $nb){
$similitudes_ttes_combi[$key1][$key2] += $combi_ref[$key3];
}
else{
$similitudes_ttes_combi[$key1][$key2] += $nb;
}
}
}
if(is_int($simili_filtre)){
if($similitudes_ttes_combi[$key1][$key2] == $simili_filtre){
$combi_simili_filtre[] = $combi;
}
}
}
}
if(is_int($simili_filtre)){
return $combi_simili_filtre;
}
else{
return $similitudes_ttes_combi;
}
}
Cette fonction va me retourner soit toutes les similitudes pour les distributions que j'ai indiquées, soit uniquement les distributions correspondant à la similitude recherchée.
Cette fonction ne me convient pas totalement car je voudrais pouvoir contrôler quelles distributions vont correspondre à la distribution ref et sa similitude. Le but étant au final d'avoir plusieurs distributions ref et leurs similitudes qui ne laisse plus qu'une distribution leur correspondant à toutes.
J'espère que mon explication est compréhensible et que mon problème a toujours un rapport avec les maths lol.
Re: Combinaisons, répartitions, distributions, similitudes
![]() par GaBuZoMeu » 06 Jan 2021, 23:34
par GaBuZoMeu » 06 Jan 2021, 23:34
Je ne parle pas le php. Je me débrouille avec python, c'est tout.
Re: Combinaisons, répartitions, distributions, similitudes
![]() par Obwil » 07 Jan 2021, 00:08
par Obwil » 07 Jan 2021, 00:08
GaBuZoMeu a écrit:Je ne parle pas le php. Je me débrouille avec python, c'est tout.
Je pense que ça peut le faire, c'est faisable de passer du php au python et inversement, en l'occurence pour mon code qui utilise uniquement des opérations simples et des boucles.
Si toi ou d'autres êtes inspirés pour proposer qqch je suis tout ouïe
A+
Re: Combinaisons, répartitions, distributions, similitudes
![]() par GaBuZoMeu » 07 Jan 2021, 16:32
par GaBuZoMeu » 07 Jan 2021, 16:32
Avec la librairie ad hoc python (itertools), et sans se casser la tête, on peut fabriquer une procédure qui va chercher toutes les distributions (de longueur donnée, sur un nombre de caractères donné) qui ont des nombres de similitudes donnés avec des distributions données.
Pour un problème assez vache concernant des distributions de longueur 12 sur 12 caractères (il y en a 1352078), trouver les distributions vérifiant 3 conditions de nombres de similitudes, ça prend un temps non négligeable, mais raisonnable :
CPU times: user 10.9 s, sys: 2.97 ms, total: 10.9 s
Wall time: 10.9 s
[[1, 1, 0, 3, 0, 0, 0, 0, 0, 2, 3, 2], [1, 1, 0, 3, 0, 0, 0, 0, 0, 2, 4, 1], [1, 1, 0, 3, 0, 0, 0, 0, 0, 3, 3, 1], [1, 1, 0, 4, 0, 0, 0, 0, 0, 2, 3, 1], [1, 2, 0, 3, 0, 0, 0, 0, 0, 2, 3, 1], [2, 1, 0, 3, 0, 0, 0, 0, 0, 2, 2, 2], [2, 1, 0, 3, 0, 0, 0, 0, 0, 3, 2, 1], [2, 1, 0, 4, 0, 0, 0, 0, 0, 2, 2, 1], [2, 2, 0, 3, 0, 0, 0, 0, 0, 2, 2, 1], [3, 1, 0, 3, 0, 0, 0, 0, 0, 2, 2, 1]]
- Code: Tout sélectionner
import itertools
def simil(L,M):
# calcule le nombre de similitudes entre deux distributions
return sum(min(L[i],M[i]) for i in range(len(L)))
def convert_dist(comb,long):
# convertit une combinaison en distribution de longueur long
bord=[-1]+list(comb)+[len(comb)+long]
return [bord[i+1]-bord[i]-1 for i in range(len(bord)-1)]
def cherche(long,car,*conds) :
# cherche les distributions de longueur long sur car caractères
# vérifiant les conditions de similitude conds données sous la forme
# (distribution, nombre de similitudes)
L=[]
combs=itertools.combinations(range(long+car-1),car-1)
for comb in combs:
dist=convert_dist(comb,long)
if all(simil(dist,cond[0])==cond[1] for cond in conds) :
L.append(dist)
return L
Pour un problème assez vache concernant des distributions de longueur 12 sur 12 caractères (il y en a 1352078), trouver les distributions vérifiant 3 conditions de nombres de similitudes, ça prend un temps non négligeable, mais raisonnable :
- Code: Tout sélectionner
%time L=cherche(12,12,([0,1,2,3,0,0,1,1,0,2,1,1],8),\
([2,1,0,1,2,2,0,0,0,1,3,0],7),\
([0,0,3,2,1,1,1,1,2,0,1,0],3))
print(L)
CPU times: user 10.9 s, sys: 2.97 ms, total: 10.9 s
Wall time: 10.9 s
[[1, 1, 0, 3, 0, 0, 0, 0, 0, 2, 3, 2], [1, 1, 0, 3, 0, 0, 0, 0, 0, 2, 4, 1], [1, 1, 0, 3, 0, 0, 0, 0, 0, 3, 3, 1], [1, 1, 0, 4, 0, 0, 0, 0, 0, 2, 3, 1], [1, 2, 0, 3, 0, 0, 0, 0, 0, 2, 3, 1], [2, 1, 0, 3, 0, 0, 0, 0, 0, 2, 2, 2], [2, 1, 0, 3, 0, 0, 0, 0, 0, 3, 2, 1], [2, 1, 0, 4, 0, 0, 0, 0, 0, 2, 2, 1], [2, 2, 0, 3, 0, 0, 0, 0, 0, 2, 2, 1], [3, 1, 0, 3, 0, 0, 0, 0, 0, 2, 2, 1]]
Re: Combinaisons, répartitions, distributions, similitudes
![]() par Obwil » 07 Jan 2021, 21:12
par Obwil » 07 Jan 2021, 21:12
GaBuZoMeu a écrit:Avec la librairie ad hoc python (itertools), et sans se casser la tête, on peut fabriquer une procédure qui va chercher toutes les distributions (de longueur donnée, sur un nombre de caractères donné) qui ont des nombres de similitudes donnés avec des distributions données.
C'est cool je vais regarder ça, merci !!
Re: Combinaisons, répartitions, distributions, similitudes
![]() par Obwil » 10 Jan 2021, 21:26
par Obwil » 10 Jan 2021, 21:26
GaBuZoMeu a écrit:Avec la librairie ad hoc python (itertools), et sans se casser la tête, on peut fabriquer une procédure qui va chercher toutes les distributions (de longueur donnée, sur un nombre de caractères donné) qui ont des nombres de similitudes donnés avec des distributions données.
Ca me donne tellement envie d'apprendre le langage Python... ça a l'air tellement plus performant pour ce que je cherche à faire.
Est-ce que tu penses qu'il est possible d'adapter ta fonction de façon à ce que pour une distribution donnée on puisse récupérer toutes les distributions qui contiennent x valeurs en commun ?
Par exemple :
- 012 et 2 valeurs donnera les distributions suivantes : 011, 002
- 0211 et 2 valeurs donnera : 0110, 0200, 0011, 0101
- 03110 et 3 valeurs donnera : 03000, 01110, 02100, 02010
- 03110 et 2 valeurs donnera : 02000, 01100, 00110, 01010
Re: Combinaisons, répartitions, distributions, similitudes
![]() par GaBuZoMeu » 11 Jan 2021, 11:28
par GaBuZoMeu » 11 Jan 2021, 11:28
Obwil a écrit:Est-ce que tu penses qu'il est possible d'adapter ta fonction de façon à ce que pour une distribution donnée on puisse récupérer toutes les distributions qui contiennent x valeurs en commun ?
C'est ce que fait la procédure que j'ai écrite, sans qu'il y ait besoin de l'adapter : elle retourne la liste des distributions qui satisfont des conditions de similitude avec un nombre fini de distributions données.
Par contre, ce que tu fais dans tes exemples, c'est autre chose : partant d'une distribution de longueur n sur p caractères (autrement dit, une combinaison avec répétition de n caractères parmi p), tu fais la liste des distributions de longueur x qu'elle contient (des sous-combinaisons avec répétitions de x caractères parmi p).
On peut bien sûr écrire une procédure qui fait ça, mais à mon avis ce n'est pas ce qui serait souhaitable.
Si j'ai le temps, je reviendrai avec une procédure plus utile.
Re: Combinaisons, répartitions, distributions, similitudes
![]() par Obwil » 11 Jan 2021, 12:12
par Obwil » 11 Jan 2021, 12:12
J'ai trouvé une solution mais qui n'est pas la plus performante, car elle crée beaucoup de solutions en trop qu'il faut supprimer par la suite.
- Code: Tout sélectionner
function distributions_possibles($n_valeurs, $x_entrees, $combi_presences = array()) {
if ($n_valeurs == 1) {
$combi_presences[] = $x_entrees;
return array($combi_presences);
}
$combinaisons = array();
// on fait appel à une fonction récursive pour générer les distributions
for ($y = 0; $y <= $x_entrees; $y++) {
$combinaisons = array_merge($combinaisons, distributions_possibles(
$n_valeurs - 1,
$x_entrees - $y,
array_merge($combi_presences, array($y))));
}
return $combinaisons;
}
function check_possibilites($distribution, $similitude){
$all_distri = distributions_possibles(count($distribution), $similitude);
$possibilites = [];
foreach($all_distri as $key => $distri){
$verif = true;
for($x = 0; $x < count($distri); $x++){
if($distri[$x] > $distribution[$x]){
$verif = false;
}
}
if($verif){
$possibilites[] = $distri;
}
}
return $possibilites;
}
Re: Combinaisons, répartitions, distributions, similitudes
![]() par GaBuZoMeu » 11 Jan 2021, 13:50
par GaBuZoMeu » 11 Jan 2021, 13:50
Que retourne ta procédure ?
Peux-tu donner un exemple d'exécution ?
Peux-tu donner un exemple d'exécution ?
Re: Combinaisons, répartitions, distributions, similitudes
![]() par Obwil » 11 Jan 2021, 17:43
par Obwil » 11 Jan 2021, 17:43
GaBuZoMeu a écrit:Que retourne ta procédure ?
Peux-tu donner un exemple d'exécution ?
Par rapport à la fonction précédente, cette fonction va créer des distributions dont le total est le nombre de similitudes et non la longueur (dans mon exemple, pour une distribution de 7 valeurs donc longueur 7, elle va créer des distributions de 3 valeurs). J'ai du mal à exprimer réellement ce qu'elle fait
Voici un exemple :
- Code: Tout sélectionner
$distri = [1,0,0,1,3,0,2];
$similitude = 3;
var_dump(check_possibilites($distri, $similitude));
//Output :
array (size=11)
0 =>
0000102
1 =>
0000201
2 =>
0000300
3 =>
0001002
4 =>
0001101
5 =>
0001200
6 =>
1000002
7 =>
1000101
8 =>
1000200
9 =>
1001001
10 =>
1001100
Re: Combinaisons, répartitions, distributions, similitudes
![]() par GaBuZoMeu » 11 Jan 2021, 18:07
par GaBuZoMeu » 11 Jan 2021, 18:07
OK, merci. Et que fais-tu avec ça ?
Re: Combinaisons, répartitions, distributions, similitudes
![]() par Obwil » 11 Jan 2021, 18:44
par Obwil » 11 Jan 2021, 18:44
GaBuZoMeu a écrit:OK, merci. Et que fais-tu avec ça ?
En fait je suis en train de créer un jeu qui consiste à retrouver une combinaison secrète à partir d'un ensemble de combinaison dont chacune possède un nombre : le nombre de similitudes avec la combinaison secrète.
Au lieu de travailler directement sur les combinaisons je travaille sur leurs distributions, cela empêche d'avoir des doublons inutiles.
Actuellement je sais générer un ensemble de distributions + similitudes qui permet de n'avoir qu'une solution, mais pour vérifier la solution unique ma méthode consiste à tester chaque distribution et sa similitude avec les autres pour voir lesquelles elle élimine, c'est pas terrible.
Grace à cette nouvele fonction je sais quelles solutions sont permises par chaque distribution et sa similitude, et ça va me permettre de pouvoir de mieux aboutir à une solution unique et aussi de mettre en place une méthode de résolution pour chaque ensemble qui me donnera peut-être une indication sur sa complexité.
Egalement j'espère pouvoir gérer le nombre de distribution + similitude à faire intervenir, afin de pouvoir influencer sur le niveau de difficulté.
36 messages
- Page 1 sur 2 - 1, 2
Qui est en ligne
Utilisateurs parcourant ce forum : Aucun utilisateur enregistré et 5 invités
Tu pars déja ?
Fais toi aider gratuitement sur Maths-forum !
Créé un compte en 1 minute et pose ta question dans le forum ;-)
Identification
Pas encore inscrit ?
Ou identifiez-vous :